(注意)本記事では自身の経験に基づいた個人の意見を述べています。DynamoDBがアジャイル開発に不向きであると主張するものではありません。
はじめに
昨今、システム開発の手法として、アジャイル開発がよく取り入れられるようになりました。
私も何度かアジャイル開発の案件に関わってきましたが、中でもアジャイルと相性が良いサーバレスアーキテクチャがよく採用されます。 そして、データベースの選択に際しては、サーバレスと相性が良いDynamoDBがよく採用されています。
しかし、アジャイルだからと言う理由だけで安易にDynamoDBを選んで、開発を進めてしまうと思わぬ落とし穴があります。
今回は実際にプロジェクトで経験した話を踏まえながら、どのようにデータベースの選定を行うべきなのか考察したいと思います!
アジャイル開発とは
アジャイル開発はソフトウェアの開発手法の一つで、動くものを迅速に作成し、顧客と頻繁にコラボレーションしながら、変更に容易に適応することに重点を置きます。
開発手法として、よく日本ではウォーターフォール開発と比較されます。
ウォーターフォール開発は、ソフトウェア開発ライフサイクルの各工程を一つずつ順番に進める手法です。
工程が明確に定義されているため、プロジェクトの計画や進捗管理が容易である一方、開発途中での要求や要件の変更に対応しにくいということがあります。
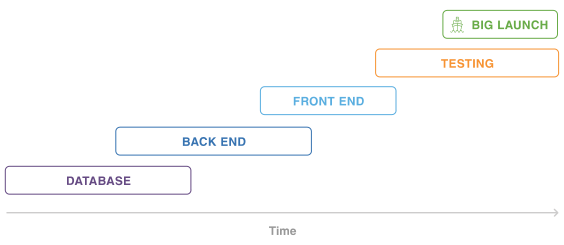
一方、アジャイル開発は、ソフトウェア開発のプロセスを短期間のイテレーションに分割し、要件定義から設計、開発、リリースまでを何回も繰り返します。
現代はVUCAの特徴を持つ時代です。
ビジネスモデルが一ヶ月後に大きく変わる可能性があるこの時代に、変化に強い開発手法としてアジャイル開発は多くの企業で取り入れられています。
アジャイルで開発する場合、ソフトウェアを市場に対してより素早く市場に送り出し、顧客からのフィードバックを得ながら価値を見つけ出していくことが求められます。 そのため、開発からリリースまでの速度が早く、変化に強いソフトウェアアーキテクチャを選定することが求められます。 サーバレスアーキテクチャはその名の通り、サーバの構築、管理が不要であるため、より迅速に開発ができるとともに、 使用量に応じて課金されるため、初期投資を抑えて「スモールスタート」が可能であることから、アジャイル開発との相性が良いと言えるでしょう。
AWSを使用してサーバレスアーキテクチャを構築する場合、サーバレスのバックエンド処理領域にLambdaが主に使用され、 データベースとしてはLambdaとの相性が良いDynamoDBが採用されることが多いです。
DynamoDBとは
DynamoDBとは、ハイパフォーマンスなアプリケーションをあらゆる規模で実行するために設計されたフルマネージドでサーバーレスの key-value NoSQL データベースです。
DynamoDBは次に記載するような特性を持つことにより、イベント駆動で動的にスケールするLambdaと相性が良いとされています。
まず、DynamoDBは分散データベースとして設計 されているため、 リレーショナルデータベースにありがちな「コネクション数の制限」の問題を持ちません 。

また、DynamoDBは動的にスケーリングし、データの読み書きの需要に応じて自動的にリソースを調整することができます。
アジャイル開発でDynamoDBを使用する際の落とし穴
さて、このように一見すると、アジャイル開発と相性の良いように見えるDynamoDBですが、アジャイル開発とは相性が悪い設計原則が存在します。
DynamoDBの公式ドキュメントには、設計原則について、以下のように記されています。
DynamoDB の場合は答えが必要な質問が分かるまで、スキーマの設計を開始すべきではありません。ビジネス上の問題とアプリケーションのユースケースを理解することが不可欠です。
一方で、アジャイルの原則として、要求の変更はたとえ開発の後期であっても歓迎するとされています。
例えば、プロダクトオーナーから仕様変更の要求があったとしたら、それに対してソフトウェアも適応するように変更する必要があります。
このような互いの性質の相違があると、どうなるでしょうか。
ここで私の関わっていたプロジェクトで実際に起きた出来事を例に見ていきたいと思います。
プロジェクト事例
私のプロジェクトではユーザ情報をDynamoDBで下記のように管理していました。
(説明のためにかなり簡素化しているもので、実際とは異なります)
※ PK: パーティションキー SK:ソートキー
| ユーザーID(PK) | メールアドレス(SK) | 性別 | 誕生日 |
|---|---|---|---|
| A123 | A123@example.com | male | 19900101 |
| B456 | B456@example.com | female | 19920115 |
| C789 | C789@example.com | male | 19881212 |
すると、ある日プロダクトオーナーより次のような要求がありました。
「性別や誕生日でユーザを検索できるようにしたい」
この要求に対応するためにはいくつか方法があります。
- Scan処理で、性別や誕生日でフィルタリングしたデータを取得する
- グローバルセカンダリインデックス(GSI)を追加することで対象キーでクエリ可能にする
一見、上記の方法で良いように思えますが、問題点があります。
まず1つ目のScan処理ですが、Scan処理のフィルタ設定はデータを一度全件取得してから設定の条件でフィルタするため、コストが増加してしまうことや、取得データがScan処理の上限である1MBに達してしまう可能性があります。
また2つ目のGSIを追加するについてですが、今のスキーマ設計ですと、下記のように性別、誕生日、それぞれにGSIを設定する必要があります。
| ユーザーID(PK) | メールアドレス(SK) | 性別(GSI-1-PK) | 誕生日(GSI-2-PK) |
|---|---|---|---|
| A123 | A123@example.com | male | 19900101 |
| B456 | B456@example.com | female | 19920115 |
| C789 | C789@example.com | male | 19881212 |
GSIを追加するということは、属性データがセカンダリインデックスに射影されることを意味します。
簡単に言い換えると、新しいプライマリーキーを持つ仮想的なコピーテーブルを作成するようなものです。
すなわち、GSIを1つ追加するということは、最大で元テーブルの2倍のデータストレージサイズになってしまうことを意味し、コスト増加の要因となり得ます。
以上の要因から、DynamoDBは要件が明確になるまで、スキーマの設計を開始すべきではないことが推奨されているのです。
結局、私のプロジェクトではこのような追加要求によって、泣く泣く、どちらかの方法を選択、もしくは再設計せざる負えない状況になってしまいました...
補足
データモデルの追加等の要求により、新しくテーブルを作成する必要が出た場合も注意が必要です。
DynamoDB はテーブル単位で個別のインフラストラクチャの扱いになってしまうため、
テーブル単位で、設定、監視、アラーム、およびバックアップが必要になり、運用コストが増加する可能性があります。*4
DynamoDBを選定するときの考慮点
上記に記載したような、DynamoDBを選択すべきではなかった!と後々発覚してしまうようなことを避けるためにはどうすれば良いのでしょうか。
以下に設計時に考慮が必要な2つのポイントを記載します。
1. 要件が確実に変わらない、かつDynamoDBであることによるメリットが強いものにしか使用しない
先に述べたようにDynamoDBはスキーマ設計の難しさがある反面、特定のユースケースにおいては優れた機能・非機能性を発揮します。
個人的な見解ですが、特に下記のデータを使うようなユースケースではRDBよりもDynamoDBのほうが向いていると思います。
時系列データ等の項目が変わる可能性が高いデータ(DynamoDBがスキーマレスである特性と相性が良い)
一時的なデータで一定時間経過後に削除が求められるデータ(DynamoDBのTTL機能と相性が良い)
2. 要件が固まらないものについてはRDBを選択する
RDBは、SQLを用いた複雑なデータ処理を得意とし、新しいテーブルを追加しても高い性能を維持できるという利点があります。
ただし、DynamoDBとは異なり、RDSやAurora等のRDBではコネクション数や性能がスケールはサポートされていないため、 Aurora ServerlessやRDS Proxyを組み合わせることが必要です。
Aurora Serverlessは、Auroraのデータベースが使用状況に応じて自動でコンピューティング性能を調整する機能を提供します。
また、RDS Proxyはマネージドなデータベースプロキシサービスであり、クライアントとのコネクション数に応じてコネクションプーリングを自動でスケールします。
RDS ProxyはAurora Serverless v2で利用可能です。
Aurora ServerlessとRDS Proxyを組み合わせた構成は下記の通りです。

まとめ
この記事ではアジャイル開発においてDynamoDBを選択することの問題点や考慮点について自身の経験をもとに紹介しました。
アジャイル開発は柔軟性と迅速な市場への提供とフィードバックのサイクルを重要ですが、それをサポートするデータベース等のサービス選定もその成功に影響することがわかったかと思います。
Amazon CTOのWerner Vogelsは次のように述べています:
A one size fits all database doesn't fit anyone (万能なデータベースは存在しない)
この言葉の通り、データベースの選択は一つのスタンダードに縛られるべきではなく、 それぞれのデータベースの特性を理解し、アジャイル開発の要請に合わせて適切に活用することを心がけたいなと思いました。