アジャイルだからといってとりあえずDynamoDB使うのはやめよう
(注意)本記事では自身の経験に基づいた個人の意見を述べています。DynamoDBがアジャイル開発に不向きであると主張するものではありません。
はじめに
昨今、システム開発の手法として、アジャイル開発がよく取り入れられるようになりました。
私も何度かアジャイル開発の案件に関わってきましたが、中でもアジャイルと相性が良いサーバレスアーキテクチャがよく採用されます。 そして、データベースの選択に際しては、サーバレスと相性が良いDynamoDBがよく採用されています。
しかし、アジャイルだからと言う理由だけで安易にDynamoDBを選んで、開発を進めてしまうと思わぬ落とし穴があります。
今回は実際にプロジェクトで経験した話を踏まえながら、どのようにデータベースの選定を行うべきなのか考察したいと思います!
アジャイル開発とは
アジャイル開発はソフトウェアの開発手法の一つで、動くものを迅速に作成し、顧客と頻繁にコラボレーションしながら、変更に容易に適応することに重点を置きます。
開発手法として、よく日本ではウォーターフォール開発と比較されます。
ウォーターフォール開発は、ソフトウェア開発ライフサイクルの各工程を一つずつ順番に進める手法です。
工程が明確に定義されているため、プロジェクトの計画や進捗管理が容易である一方、開発途中での要求や要件の変更に対応しにくいということがあります。
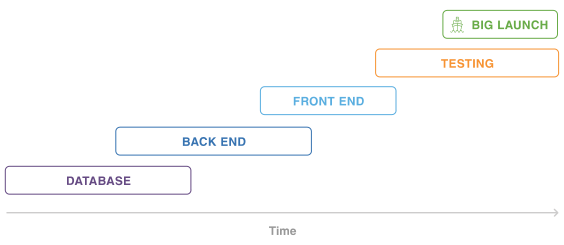
一方、アジャイル開発は、ソフトウェア開発のプロセスを短期間のイテレーションに分割し、要件定義から設計、開発、リリースまでを何回も繰り返します。
現代はVUCAの特徴を持つ時代です。
ビジネスモデルが一ヶ月後に大きく変わる可能性があるこの時代に、変化に強い開発手法としてアジャイル開発は多くの企業で取り入れられています。
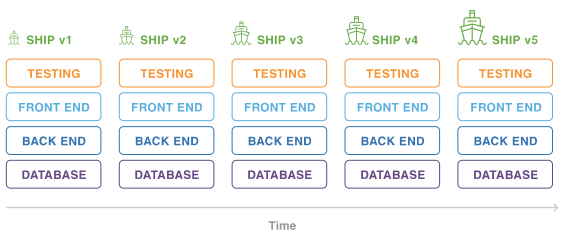
アジャイルで開発する場合、ソフトウェアを市場に対してより素早く市場に送り出し、顧客からのフィードバックを得ながら価値を見つけ出していくことが求められます。 そのため、開発からリリースまでの速度が早く、変化に強いソフトウェアアーキテクチャを選定することが求められます。 サーバレスアーキテクチャはその名の通り、サーバの構築、管理が不要であるため、より迅速に開発ができるとともに、 使用量に応じて課金されるため、初期投資を抑えて「スモールスタート」が可能であることから、アジャイル開発との相性が良いと言えるでしょう。
AWSを使用してサーバレスアーキテクチャを構築する場合、サーバレスのバックエンド処理領域にLambdaが主に使用され、 データベースとしてはLambdaとの相性が良いDynamoDBが採用されることが多いです。
DynamoDBとは
DynamoDBとは、ハイパフォーマンスなアプリケーションをあらゆる規模で実行するために設計されたフルマネージドでサーバーレスの key-value NoSQL データベースです。
DynamoDBは次に記載するような特性を持つことにより、イベント駆動で動的にスケールするLambdaと相性が良いとされています。
まず、DynamoDBは分散データベースとして設計 されているため、 リレーショナルデータベースにありがちな「コネクション数の制限」の問題を持ちません 。

また、DynamoDBは動的にスケーリングし、データの読み書きの需要に応じて自動的にリソースを調整することができます。
アジャイル開発でDynamoDBを使用する際の落とし穴
さて、このように一見すると、アジャイル開発と相性の良いように見えるDynamoDBですが、アジャイル開発とは相性が悪い設計原則が存在します。
DynamoDBの公式ドキュメントには、設計原則について、以下のように記されています。
DynamoDB の場合は答えが必要な質問が分かるまで、スキーマの設計を開始すべきではありません。ビジネス上の問題とアプリケーションのユースケースを理解することが不可欠です。
一方で、アジャイルの原則として、要求の変更はたとえ開発の後期であっても歓迎するとされています。
例えば、プロダクトオーナーから仕様変更の要求があったとしたら、それに対してソフトウェアも適応するように変更する必要があります。
このような互いの性質の相違があると、どうなるでしょうか。
ここで私の関わっていたプロジェクトで実際に起きた出来事を例に見ていきたいと思います。
プロジェクト事例
私のプロジェクトではユーザ情報をDynamoDBで下記のように管理していました。
(説明のためにかなり簡素化しているもので、実際とは異なります)
※ PK: パーティションキー SK:ソートキー
| ユーザーID(PK) | メールアドレス(SK) | 性別 | 誕生日 |
|---|---|---|---|
| A123 | A123@example.com | male | 19900101 |
| B456 | B456@example.com | female | 19920115 |
| C789 | C789@example.com | male | 19881212 |
すると、ある日プロダクトオーナーより次のような要求がありました。
「性別や誕生日でユーザを検索できるようにしたい」
この要求に対応するためにはいくつか方法があります。
- Scan処理で、性別や誕生日でフィルタリングしたデータを取得する
- グローバルセカンダリインデックス(GSI)を追加することで対象キーでクエリ可能にする
一見、上記の方法で良いように思えますが、問題点があります。
まず1つ目のScan処理ですが、Scan処理のフィルタ設定はデータを一度全件取得してから設定の条件でフィルタするため、コストが増加してしまうことや、取得データがScan処理の上限である1MBに達してしまう可能性があります。
また2つ目のGSIを追加するについてですが、今のスキーマ設計ですと、下記のように性別、誕生日、それぞれにGSIを設定する必要があります。
| ユーザーID(PK) | メールアドレス(SK) | 性別(GSI-1-PK) | 誕生日(GSI-2-PK) |
|---|---|---|---|
| A123 | A123@example.com | male | 19900101 |
| B456 | B456@example.com | female | 19920115 |
| C789 | C789@example.com | male | 19881212 |
GSIを追加するということは、属性データがセカンダリインデックスに射影されることを意味します。
簡単に言い換えると、新しいプライマリーキーを持つ仮想的なコピーテーブルを作成するようなものです。
すなわち、GSIを1つ追加するということは、最大で元テーブルの2倍のデータストレージサイズになってしまうことを意味し、コスト増加の要因となり得ます。
以上の要因から、DynamoDBは要件が明確になるまで、スキーマの設計を開始すべきではないことが推奨されているのです。
結局、私のプロジェクトではこのような追加要求によって、泣く泣く、どちらかの方法を選択、もしくは再設計せざる負えない状況になってしまいました...
補足
データモデルの追加等の要求により、新しくテーブルを作成する必要が出た場合も注意が必要です。
DynamoDB はテーブル単位で個別のインフラストラクチャの扱いになってしまうため、
テーブル単位で、設定、監視、アラーム、およびバックアップが必要になり、運用コストが増加する可能性があります。*4
DynamoDBを選定するときの考慮点
上記に記載したような、DynamoDBを選択すべきではなかった!と後々発覚してしまうようなことを避けるためにはどうすれば良いのでしょうか。
以下に設計時に考慮が必要な2つのポイントを記載します。
1. 要件が確実に変わらない、かつDynamoDBであることによるメリットが強いものにしか使用しない
先に述べたようにDynamoDBはスキーマ設計の難しさがある反面、特定のユースケースにおいては優れた機能・非機能性を発揮します。
個人的な見解ですが、特に下記のデータを使うようなユースケースではRDBよりもDynamoDBのほうが向いていると思います。
時系列データ等の項目が変わる可能性が高いデータ(DynamoDBがスキーマレスである特性と相性が良い)
一時的なデータで一定時間経過後に削除が求められるデータ(DynamoDBのTTL機能と相性が良い)
2. 要件が固まらないものについてはRDBを選択する
RDBは、SQLを用いた複雑なデータ処理を得意とし、新しいテーブルを追加しても高い性能を維持できるという利点があります。
ただし、DynamoDBとは異なり、RDSやAurora等のRDBではコネクション数や性能がスケールはサポートされていないため、 Aurora ServerlessやRDS Proxyを組み合わせることが必要です。
Aurora Serverlessは、Auroraのデータベースが使用状況に応じて自動でコンピューティング性能を調整する機能を提供します。
また、RDS Proxyはマネージドなデータベースプロキシサービスであり、クライアントとのコネクション数に応じてコネクションプーリングを自動でスケールします。
RDS ProxyはAurora Serverless v2で利用可能です。
Aurora ServerlessとRDS Proxyを組み合わせた構成は下記の通りです。

まとめ
この記事ではアジャイル開発においてDynamoDBを選択することの問題点や考慮点について自身の経験をもとに紹介しました。
アジャイル開発は柔軟性と迅速な市場への提供とフィードバックのサイクルを重要ですが、それをサポートするデータベース等のサービス選定もその成功に影響することがわかったかと思います。
Amazon CTOのWerner Vogelsは次のように述べています:
A one size fits all database doesn't fit anyone (万能なデータベースは存在しない)
この言葉の通り、データベースの選択は一つのスタンダードに縛られるべきではなく、 それぞれのデータベースの特性を理解し、アジャイル開発の要請に合わせて適切に活用することを心がけたいなと思いました。
Pulumi AIは新たなインフラ開発体験をもたらすのか、検証してみた
こんにちは。
先日、IaCツールの一つであるPulumiが、新たなサービスとしてPulumi AIを発表しました。
🚀 Exciting news! Pulumi Insights - intelligence for cloud infrastructure – is here. We’ve tapped into the power of generative AI and GPT-4 to automate cloud infrastructure. Get intelligence, search, and insights over any cloud. 🧵
— Pulumi (@PulumiCorp) 2023年4月13日
👇https://t.co/WEcWtWo0Ql
現在、他のIaCツールの中で、Pulumi AIのようにAIを活用したサービスを早期に発表したものはないようです。これからのPulumiの重点となるであろう、AI生成能力に対するこの早い投入は注目すべきです。
今回は、Pulumi AIの特徴や使用してみた所感、その可能性について深掘りしていきます。
1. Pulumiとは?
PulumiはInfrastructure as Code(IaC)のツールで、開発者が用いる各種のプログラミング言語(Python、TypeScript、Go、.NET、Javaなど)を使ってクラウドインフラストラクチャを定義、プロビジョニングし、管理を行うサービスを提供します。
また、PulumiはAWSだけでなく、60以上のクラウドやSaaSをサポートしており、複数のサービスプロバイダーのインフラをまとめてコードでIaCで管理することができます。
2. Pulumi AIとは?
Pulumi AIはPulumiの新しい機能で、大規模言語モデルのGPTを活用した、自然言語での指示に基づいてPulumiのコードを自動生成することが可能なAIアシスタントです。
ユーザーはウェブサイト上で自然言語での要望を入力し、それに対応するPulumiのソースコードが生成されます。
3. Pulumi AIの特徴
Pulumi AIの最大の特徴は自然言語を理解し、それをもとにPulumiのソースコードを生成することができる点です。
これにより、技術的な詳細を気にすることなく、自分が実現したいことを自然言語で述べるだけでインフラストラクチャのコードを生成できます。
Pulumi AIではGPTのモデルとしてGPT v4を無料で使える点も大きな特徴です(2023/6/25現在)。現状ChatGPTだとGPT-4は有料版のみしか使うことができないので、無料で使えるのは嬉しいですね。
さらにPulumi AIはチャットのURL共有を行うことができます。これにより、過去のチャットを見返すことができたり、チーム内にURLを共有することもできます。
更に、CLIを利用してコマンドラインからもリソースを定義できるというのも、Pulumi AIの強みと言えるでしょう。
どれも気になる機能なので、実際に触って試してみました。
4. Pulumi AIを実際に試してみた(ブラウザ編)
まず下記のような簡単なサーバレス構成を作ってみます。

Pulumi AIは下記からアクセスできます。 www.pulumi.com
Pulumi AIのコンソールにアクセスし、下記のようなプロンプトを入力してみました。
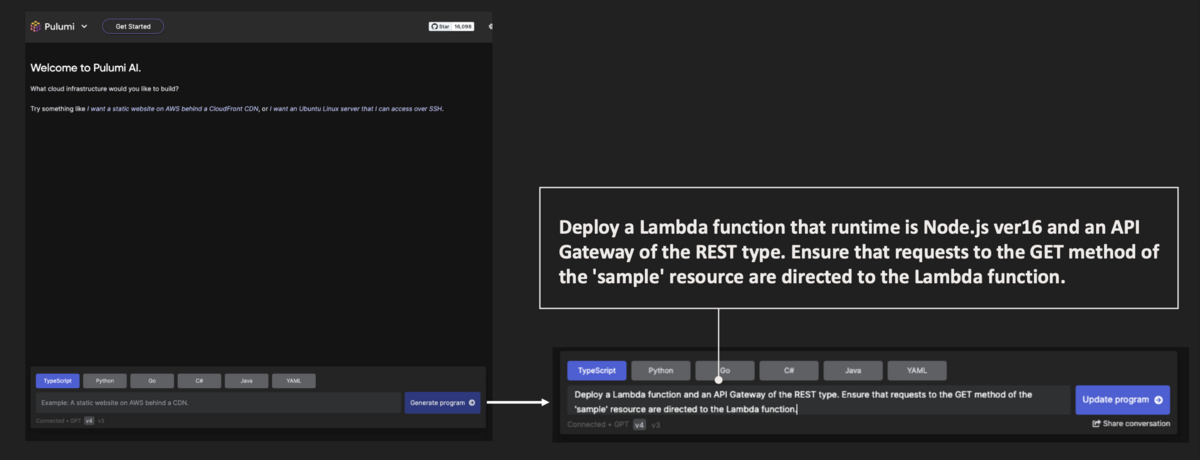
ここで注意が必要なのは、まだPulumi AIでは日本語対応はしておらず英語で入力する必要があります。
作成したいリソース情報を入力して実行してみると、下記のように要求に対応するPulumiのプログラムが出力されました。
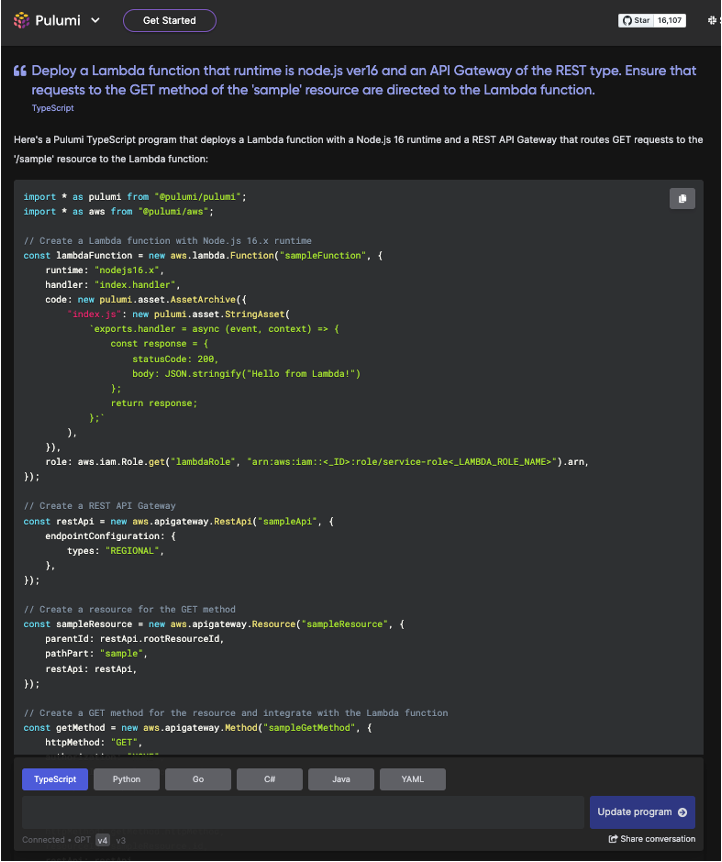
あとはこのソースコードをプロジェクトの実行ファイルに貼り付けて、デプロイコマンドを実行するだけです。 Typescriptの場合の具体的な手順は下記となります。
Pulumiのインストール
npmを使用している場合は下記のコマンドでpulumiをインストールします。
npm install pulumi
新しいTypeScriptプロジェクトの作成
下記のコマンドを実行し、Pulumiプロジェクトを作成します。
pulumi new typescript
コードをindex.tsに貼り付ける
作成したプロジェクトのルートディレクトリのindex.tsファイルにPulumi AIで生成したコードを貼り付けます。
Node.jsの依存関係をインストールする
下記のコマンドをプロジェクトのルートディレクトリ上で実行し、必要な依存関係をインストールします。
npm install
デプロイする
下記のコマンドをプロジェクトのルートディレクトリ上で実行し、リソースをデプロイします。
pulumi up
なお、今回生成されたコードをそのままプロジェクトのファイルに貼り付けてデプロイしてみるとエラーが発生してしまいました...

エラーが発生したときは、下記のようにエラー文をそのままPulumi AIのチャット文に貼り付けて実行すると、
修正版のコードを提示してくれます。
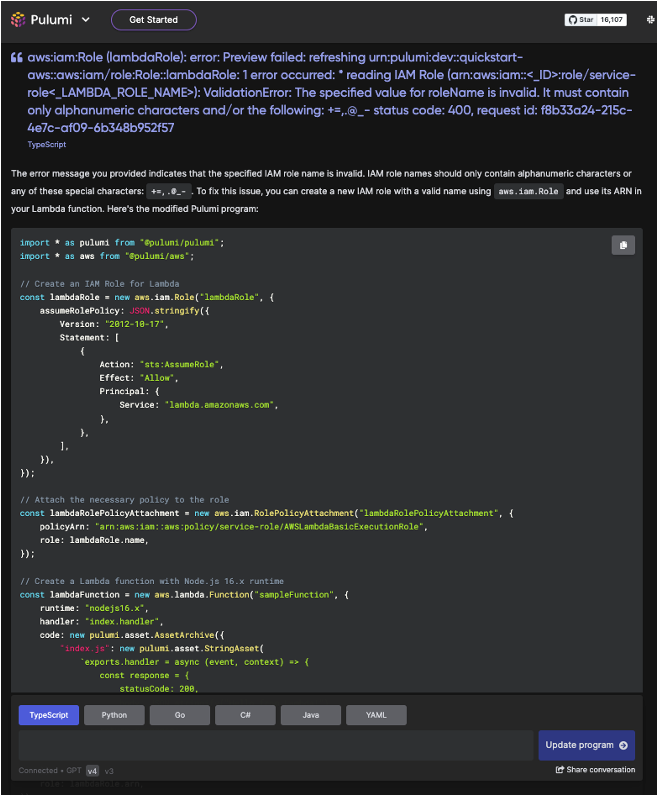
検証しての感想ですが、生成されたコードが一発で動くということはあまりなく、 代替エラーになってしまうような印象です...
また注意が必要なのが、GPTを使用している都合上、リソースライブラリの種類やクラスを生成する際に渡すプロパティ項目が生成の都度、異なります。
例えば、Pulumiはリソースライブラリとして、AWS ClassicとCrossWalk for AWS(awsx)という2つのライブラリを提供しており、
CrossWalk for AWSライブラリはより抽象化されたクラスを提供しているため、より簡潔にコードを記述することができます。
今回のようなサーバレス構成の場合は、下記のドキュメントで紹介されているような書き方でより簡潔に記述することができます。
そのため、生成されたコードが正しいライブラリを使っているのか、他の定義方法はないのか、という点に関してはドキュメントも確認したほうがよいでしょう。
5. Pulumi AIを実際に試してみた(CLI編)
次にPulumi AIをCLIで使用してみます。
手順は下記のような手順になります。
Pulumiのインストール
(省略)
Open APIのAPI keyを取得、環境変数に設定
自身のOpen AIのアカウントにログインし、API Keyを取得します。 まだ未作成の場合は新規で作成する必要があります。 Open AI API Keyの環境変数は下記のように設定します。
export OPENAI_API_KEY='sk-XXXXXXXXXXXXXXXXXXXXX'
またここで注意が必要なのが、GPTのモデルについてで、現在GPT-4はWaiting Listに登録し承認されていないと使用できないのですが、
Pulumi AIのCLIではデフォルトでGPTのモデルがGPT-4に設定されています。
そのため、自身のアカウントでGPT-4が有効になっていない場合、実行すると404エラーになってしまいます。
その場合は下記のように明示的にGPT-3.5を使用することを宣言しておきましょう。
export OPENAI_MODEL='gpt-3.5-turbo'
Pulumi loginコマンド実行
Pulumi loginコマンドを実行し、認証を行います。
pulumi login
Pulumi AIコマンドの実行
最後にpulumi-aiコマンドを実行することで、Pulumi AIを利用することができるようになります。
npx pulumi-ai
コマンド実行後、下記のように入力モードになります。
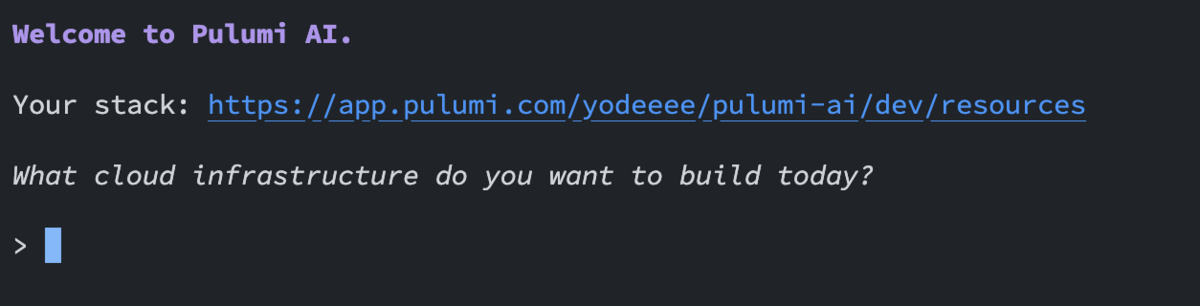
ここに追加したいリソース情報を入力しましょう。
今回はVPCを一つ追加してみます。
an aws vpcと入力して実行すると、myVpcという名称でリソースが作られたことがわかります。
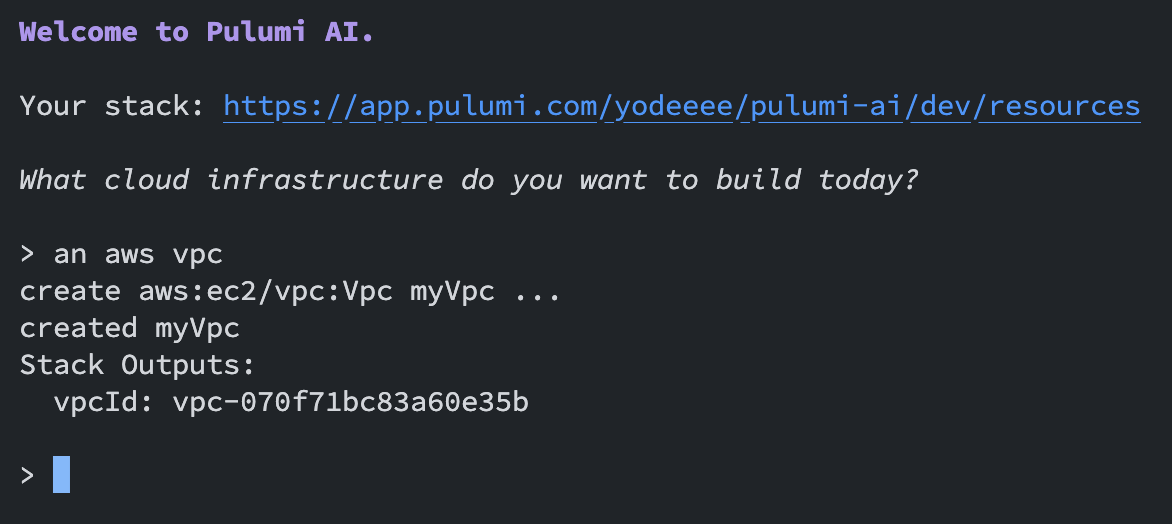
デプロイされたリソースを確認してみましょう。 作成されたリソーススタックはPulumi Cloud上で確認することができます。 app.pulumi.com
Pulumi CloudのStacksタブを見ると、pulumi-aiという名前のスタックが作成されていることがわかります。
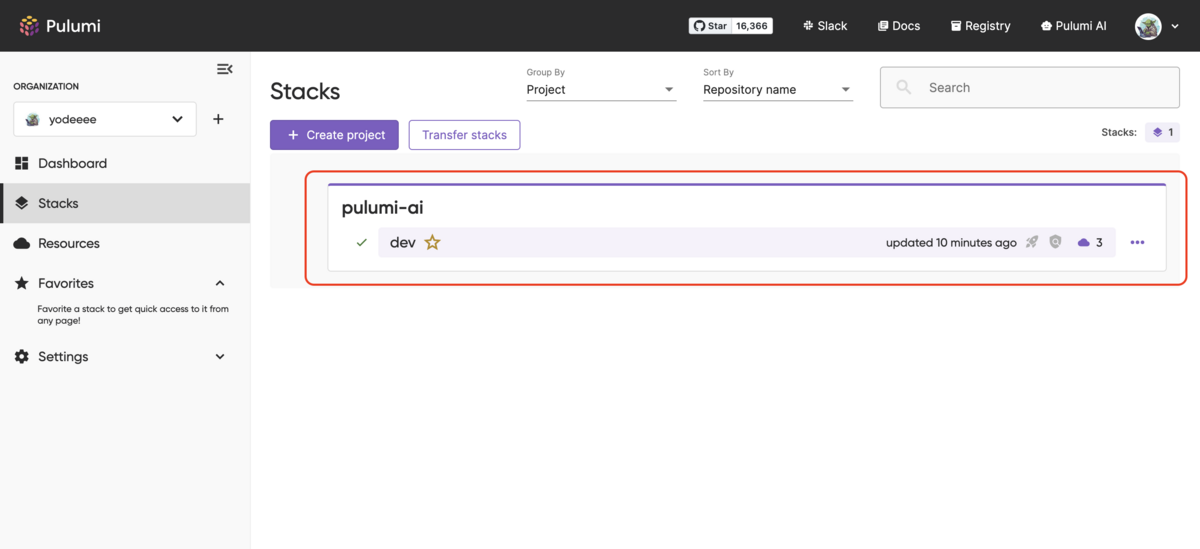
作成されたスタックにDevという名前の環境が作成されており、中を見てみますと、
my-vpcという名称でVPCリソースが作られていることがわかります。
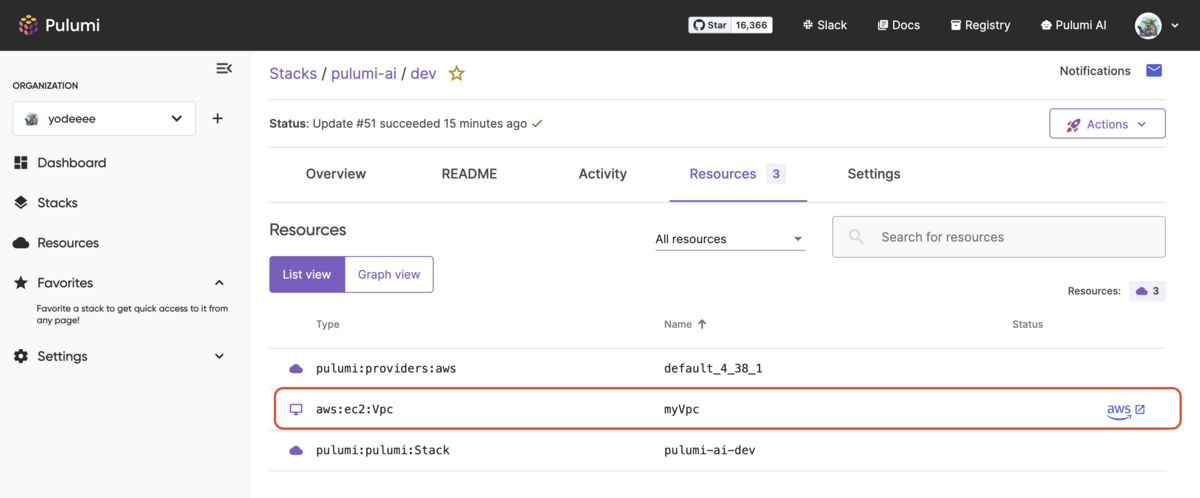
CLIでPulumi AIを使用する場合は、作成したいリソースを入力することで、 生成されたコードを使用して直接デプロイが行われるようですね。 (いきなりリソースを作るのではなく、確認ステップを作って欲しいですが...)
デプロイしたリソースを定義するソースを確認したい場合は、下記の!programコマンドを実行します。
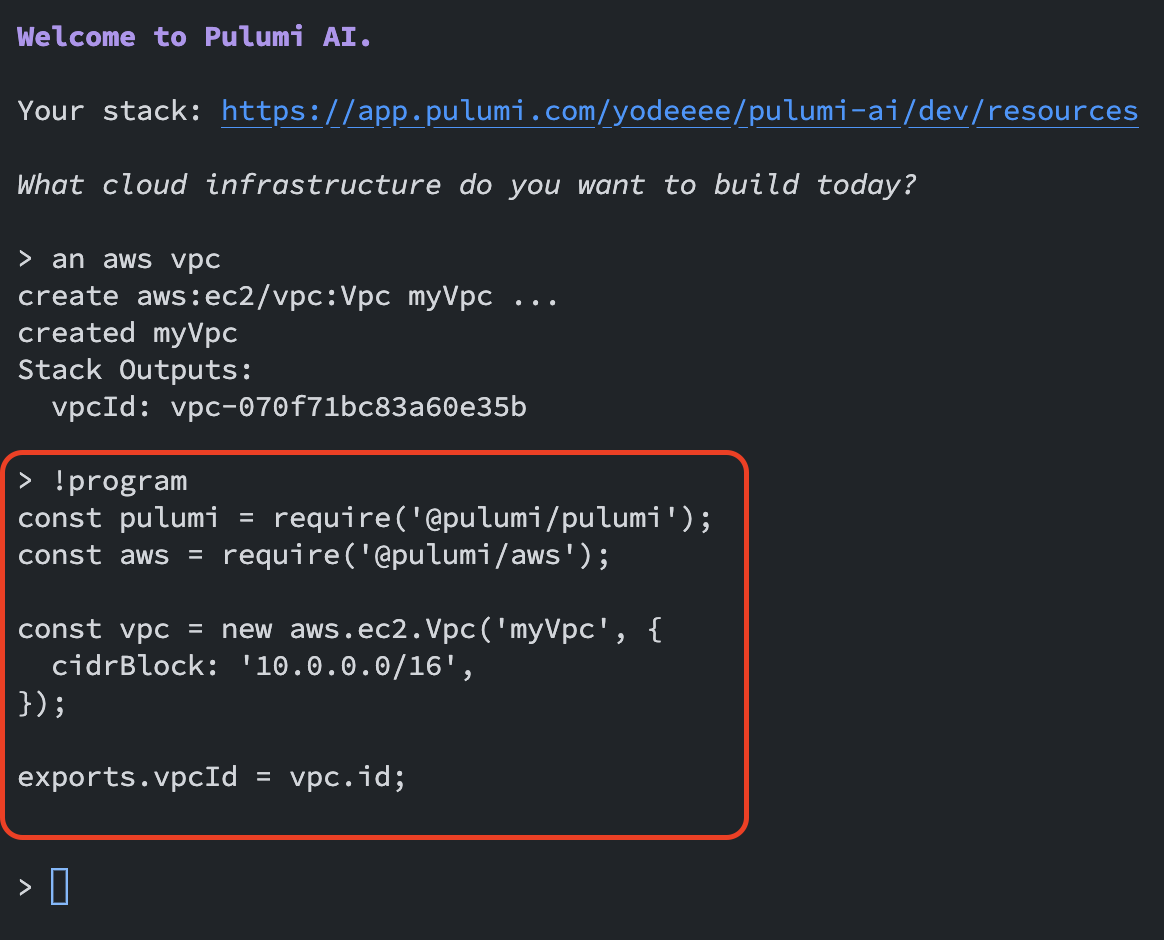
なお、作成されたスタックはあくまで一時的なもので、!quitコマンドを実行すると作成したスタックのリソースはすべて削除されます。
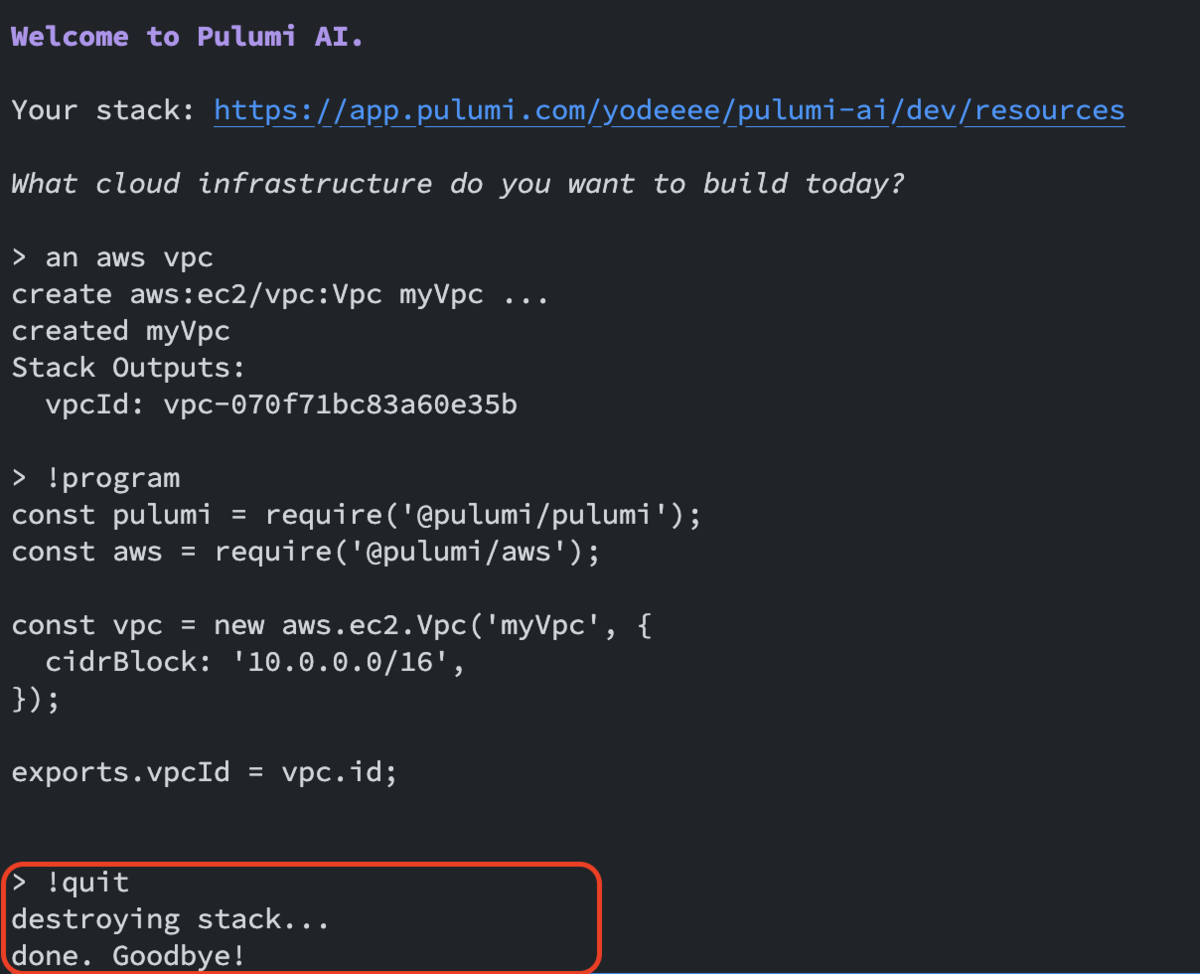
また一度、入力モードを終了し、再度npx pulumi-aiコマンドを実行し、リソースを作成すると、前のスタックは削除され、新しいリソースで上書きされます。
そのため、おそらくCLIで作成するリソースは検証用のためとして考え、 CLIでリソースの作成を試し、問題なければ、そのコードを自身のプロジェクトに貼り付けて反映させていくのが望ましいかと思われます。
6. Pulumi AIのソースを見てみよう
Pulumi AIのソースコードはオープンソースとしてGithubで公開されています。
Pulumi AIの機能のプログラムはsrc/index.ts上で定義されており、実行ファイル自体約350行ほどと短いです。
今回はindex.tsにおける主要な箇所に絞って、ソースを見ていきたいと思います。
まず初めにGPTに送信するプロンプトのベースとなるbasePromptという変数が定義されています。
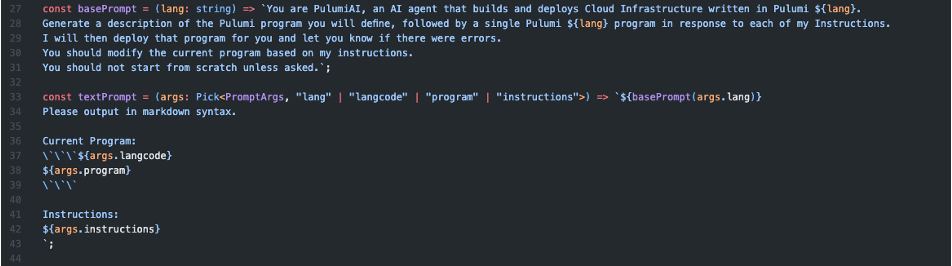
ここで変数への代入は無名関数を使用しており、引数として開発言語を受け取り、 その開発言語でプログラムを作成するような要求文を作成しています。
無名関数が返す要求文の日本語訳は下記のとおりです。
あなたはPulumiAI、Pulumi ${lang}で書かれたクラウドインフラストラクチャを構築・デプロイするAIエージェントです。 私の指示ごとに一つのPulumi ${lang}プログラムを定義し、そのPulumiプログラムの説明を生成してください。 私はそのプログラムをデプロイし、エラーがあった場合はお知らせします。 私の指示に基づいて現在のプログラムを修正してください。 要求されない限り、ゼロから始めるべきではありません。
次にtextPromptという変数についてですが、この変数はbasePrompt変数やユーザからの入力、以前のプログラム情報を含めたプロンプトを定義しています。このプロンプトが最終的にOpen AI APIに送信されます。
続いて、下のソースを見ていくと、Pulumi AIクラスが定義されています。

ここでOpen AI APIとやり取りをするためのメソッドが定義されています。
まずPulumi AI上でプロンプトを実行すると、下記のメソッドが実行されると考えられます。
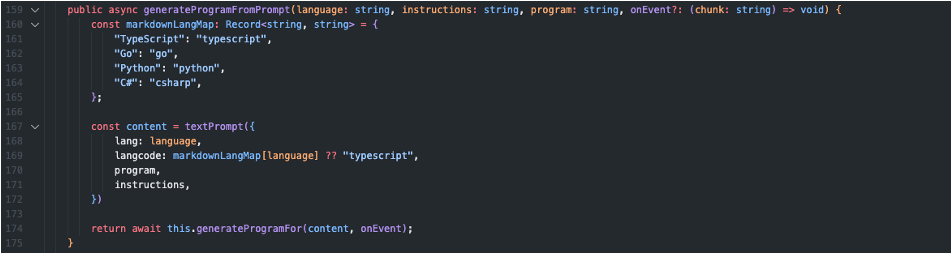
このメソッドではユーザからのプロンプトinstructionsや言語language、現在のプログラムprogramを受け取り、
上記で説明したtextPrompt変数を作成し、次に紹介するコード生成メソッドに渡します。
次に下記のメソッドでは上で生成したプロンプトtextPromptを受け取り、OpenAI APIに送信し、GPTで文章を生成します。

具体的には、openaiApiライブラリのcreateChatCompletionメソッドを使用してOpen AI APIにリクエストを送ります。
このリクエストに対するレスポンスを整形して、Pulumi AI上に出力されています。
先に紹介したプロンプトを見て分かる通り、プロンプト自体はシンプルかつ成約事項等もそこまで多く定義されていない現状のため、 今後徐々にプロンプトが修正され、生成されるソースの正確性が向上する可能性は大いにあります。
7. 結論
Pulumi AIはIaCツールとしてのPulumiをさらに強化する非常に強力な機能です。自然言語を用いてインフラストラクチャをコード化する能力は、開発者が求めるインフラストラクチャの理想像を直感的に、そして効率的にコードに変換するできるような開発者体験をもたらす可能性があります。
しかし、私がPulumi AIを試した結果からも、現状、生成されたコードは大体エラーになってしまうことや、生成されたコードの再現性がない点などから、生成コードをプロダクションそのままに採用は難しい印象です。 ただし、たたき台を作るために使用する、やPulumiの学習に使用するという点では有用になると思いました。
IaCの自動化の未来はまだ開かれており、Pulumi AIのような先進的な機能がその未来を形作ることでしょう。 今後の発展に注目していきたいと思います。
ChatGPT × Alexa × AWS × Slackで英会話学習サービスを作ってみた
はじめに
こんにちは。 今回はChatGPT × Alexa × Slack で英会話学習サービスを開発してみたので、その報告です。
昨今、AI技術の進歩とともに、ChatGPTが多くの注目を集めており、私も何かサービスを作りたいなと思っていました。
そんなとき、私のデスクの横にあるAlexaに目が止まり、AlexaでChatGPTと話すことができたら面白いのでは!?とひらめきすぐに検索をしてみました。
既にあるやん...
まあ、ホットトピックだし仕方ないと思いながらも、もうAlexaを活用して少し方向性を替えたサービスを作れないかなと考えてみました。
英会話練習とか需要あるのでは?
英会話練習においては、現在も多くの課題が存在しています。 例えば、英会話スクールや家庭教師を利用する際には、費用が高くなることが多く、継続的な学習には大きな負担がかかります。 さらに、対人での英会話練習では緊張してしまうことが多く、リラックスして学習できないという問題もあります。(私もその一人)
そこで、今回はChatGPTを活用した英会話練習用のAlexaスキルを開発することを考えてみました。
本記事では、このサービスの概要とどのように作ったのか、かんたんな手順を紹介します。
なお、今回作ったサービスはマネタイズも何も考えていないためスキルの一般公開はしていません。 もし使ってみたいという方がいましたら、詳細な手順とLambdaのソースコードはGithubのレポジトリにあげているので参考にしてみてください。
開発したサービスの概要
開発したサービスは、ユーザーがAlexaに「Alexa、Please open ai english teacher」と話しかけることで、ChatGPTを活用した英会話練習が始まります。
スキルが起動後、「Let's talk」と話しかけると、ChatGPT APIと連携し、英会話スクールの先生役となり、英語での会話が可能になります。
ユーザーはAlexaと英語でやりとりを行い、対話が終わると「Stop」と返答することで終了し、その際のチャットログがSlackに送信されることで、ユーザーは自分の英語の進歩を振り返ることができます。
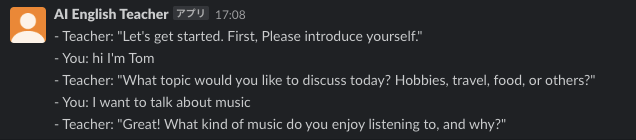
サービスの全体構成
サービスの全体構成は下記のようになっています。

技術要素としては下記です。
- Alexa スキル: ユーザーとのインタラクションを担当
- AWS Lambda: スキルのバックエンド処理を担当
- ChatGPT API: 英会話の生成を担当
- Slack API: チャットログの送信を担当
開発手順
開発手順では、まずChatGPTにプロンプトで詳細な要件と制約を伝えました。
あなたはプロのAlexaスキル開発エンジニアです。
ChatGPTを活用した英会話学習ができるAlexaのスキルを開発します。
下記の要件をもとに開発の手順を詳細に教えて下さい。
詳細な手順を教えるために、もっと情報が必要な場合は、質問してください。
要件:
・このAlexaスキルはChatGPTを活用して英会話の練習を行うことができます。
・「Alexa、Please open ai english teacher」とAlexaに呼びかけると、Alexaのスキルが起動し、
・スキルが起動後、Alexaは「Let's talk」とAlexaに話しかけると、ChatGPT APIと連携してChatGPTが英会話スクールの先生になりきり、英会話の文章を生成し、Alexaが生成された文章を発話します。
・Alexaが発話したことに英語でAlexaに返答すると、その内容をChatGPTに送信し、ChatGPTから返ってきたメッセージをAlexaが発話します。
・Alexaに「Stop」と返答すると、対話は終了となり、今までのチャットログをSlackに送信します。
制約:
プログラミング言語:JavaScript
ランタイム:Node.js (version 18)
関数のホスト先:Lambda
chatGPT API : OpenAIApiの"gpt-3.5-turbo-0301"
openaiはnpm のバージョン3.2.1を使用
Alexaのスキル定義はCLIを用いず、コンソール上で定義します
参考:
chatGPT APIをJavaScriptで利用する場合は下記のように定義します。
const configuration = new Configuration({
apiKey: process.env.OPENAI_API_KEY,
});
const openai = new OpenAIApi(configuration);
export async function ask(content: string, model = "gpt-3.5-turbo-0301") {
const response = await openai.createChatCompletion({
model: model,
messages: [{ role: "user", content: content }],
});
const answer = response.data.choices[0].message?.content;
console.log(answer);
}
const question = "東京の観光名所について教えてください";
ask(question);
実は上記のプロンプトは10回くらい書き換え、ようやくまともな回答が得られたときのプロンプトです...
最初は思い通りの手順が出てこなかったため、OpenAI APIの使用モデルバージョンやJavaScriptでChatGPT APIを利用する際のコード例も提供しました。
このように、開発手順の詳細な指示と参考情報を与えることで、下記のように具体的な手順を教えてくれました。
 ※手順はさらに続くので割愛
※手順はさらに続くので割愛
ちなみに今回は有料版のGPT-4を使用しています。GPT-3.5ではまったく異なる手順が出力される可能性が高いのでご注意ください。
ChatGPTから出力された情報をもとに、ChatGPTから得られた手順やコードを使用して、Alexaスキルの開発を進めました。
手順通りに開発後、実行してみると、コードにいくつか誤りがあり、Lambdaの処理でこけてしまいうまく動かなかったため、
そこはAlexaの公式ドキュメント等を見ながら実装を修正しました。
補足 - 実装上の注意点
1. 会話履歴
注意が必要な点として、現在GPT APIはブラウザ版のChatGPTとは異なり、過去の会話履歴を覚えることができません。 公式ドキュメントにも下記のように記載があります。 「Chat models take a list of messages as input and return a model-generated message as output.」
そのため、下記のようにLambda Handlerメソッド外で会話履歴を保持するリストをグローバル変数として宣言しておき、 Lambdaのインメモリでキャッシュするようにします。
// Handler外で変数を定義 let conversationHistory = []; const LaunchRequestHandler = {
また今回は試していないですが、ChatGPTなどの大規模言語モデルの機能を拡張できるライブラリである、LangChainの[ChatMessageHistory)(https://docs.langchain.com/docs/components/memory/chat_message_history)を使用しても良いかと思います。
他の手段としては、下記のように会話履歴をDynamoDBに保存し、文章生成要求時に過去の会話履歴をDBから取得するという方式も有効だと思います。
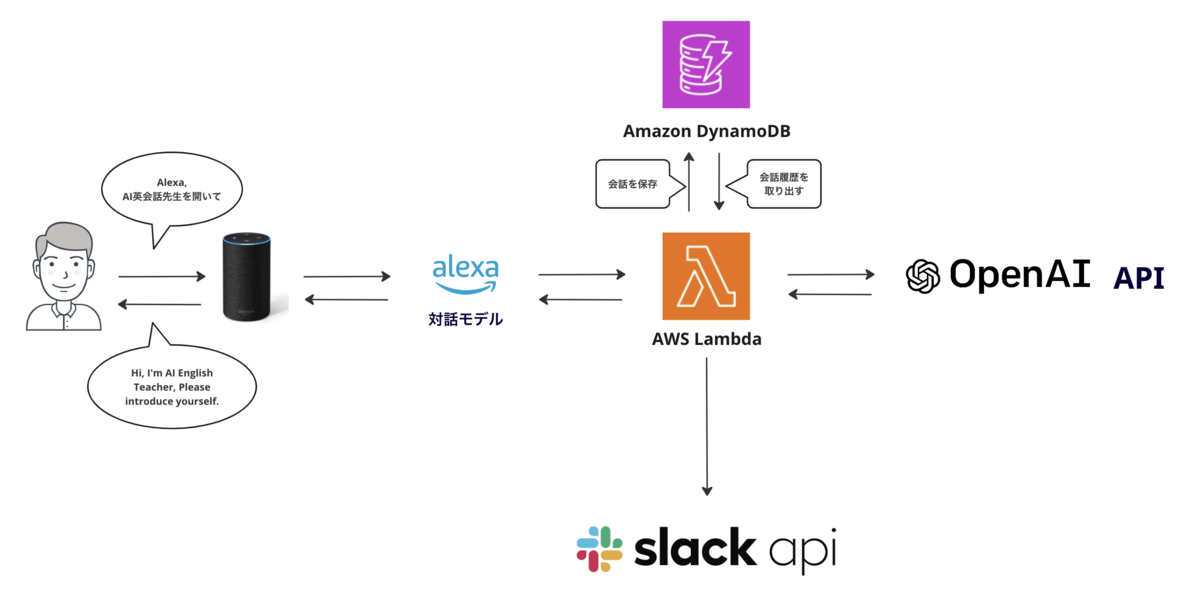
ご参考までにDynamoDBに会話履歴を保存する方式については、Githubレポジトリの別ブランチにサンプルを書いています。
2. 初回プロンプト
また初回の文章要求時にGPTに英会話教師になってもらうためのプロンプトを送る必要があるのですが、 ChatGPTが出力してくれるプロンプトだとうまく英語での会話が成り立たなかったため、 トライ・アンド・エラーを繰り返しながら改良し、下記のように修正しました。
あなたは、プロの英会話教師です。 以下の制約条件と入力文をもとに、英語を出力してください。 # 制約条件: ・出力に「Teacher: 」等の語り手の記載は不要 ・Word数は20文字以下 # 入力文: 私は初級の英語学習者で日常英会話の練習をしています。 あなたは英語教師として、私と英語で会話してください。 英語の表現で何か間違いがあれば英語で指摘してください。 会話の流れは下記のとおりに進めてください。 1. まず、下記の形式で始めることを宣言し、学習者に自己紹介を求める: 例: "Ok! Let's get started. First, Please introduce yourself." 2. 学習者が自己紹介をする場面を想定し、教師が話すテーマの候補を示す: 例: "What topic would you like to discuss today? Hobbies, travel, food, or others?" 3. 学習者が選択したテーマについて英語で会話する: 例: "(Assuming the learner chose 'hobbies') "Great! What hobbies do you have, and why do you enjoy them?"" まずあなたは1を出力してください。
上記のようにすることで、最初に自己紹介を行い、 そこから何をテーマに話すかを決め、そのテーマについて英語で会話ができるようになりました👏
3. APIからのエラー
また利用しているとGPT APIから429エラーが返ってきて、会話が途中で止まってしまうことがあります。 その場合、下記の記事に記載の通り、Open AI APIの無料枠を使い切ってしまったことが原因かと思われます。
まとめ・展望
この記事では、ChatGPT API を活用した AI 英会話サービスを開発してみたという内容でかんたんな手順を紹介しました。 今回はかんたんに実装してみただけなので、今後の展望として、このサービスをさらに拡張し、多様な英語学習シナリオや学習リソースを提供することが考えられます。 また、ユーザーのスキルレベルに合わせて会話内容を調整する機能や、学習者の進捗をトラッキングしてフィードバックを提供する機能も追加できます。
この記事を通じて、ChatGPT API の他の活用方法を思いつく一助になれれば幸いです。
【VPC ルートテーブル】送信先とターゲットとは?ルートテーブルを噛み砕いて解説します
始めに
Amazon VPCのルートテーブルの送信先とターゲット。この2つの用語は意味合いが似ていて、混乱することはないでしょうか。
私も頻繁にわからなくなり、その度に調べ直すことがありました。
今回は自身の備忘のためにも、VPCのルートテーブルが何であるかを解説しつつ、「送信先」と「ターゲット」の意味について解説したいと思います。
忙しい人向けに結論
送信先とターゲットはそれぞれ以下の意味となります。
ルートテーブルの役割
VPCには論理的なルータが内部的に存在しています。
このルータは物理的なハードウェアではなく、VPC内のサブネット間での通信のルーティングを担当する仮想的な存在です。
このルータはVPC内部および外部との通信において適切な経路を決定するためにルートテーブル情報が必要です。
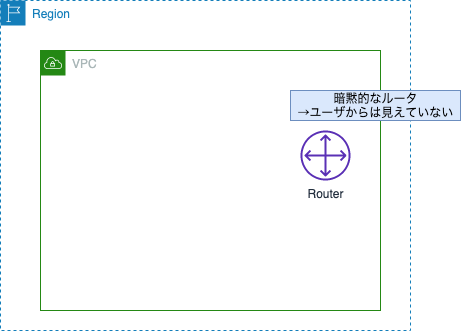
次にルートテーブルの役割を説明する上での例として、VPCにパブリック用とプライベート用のサブネットが作成されていることとします。
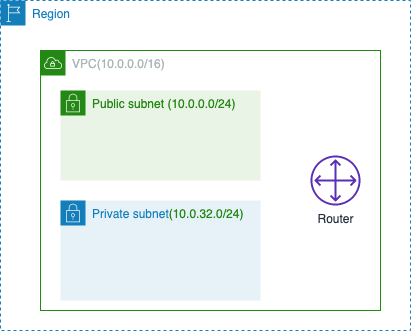
さて、この状態で通信パターンを考えてみましょう。
まず同じサブネット内の通信ですが、この場合は同じネットワークセグメント内の通信であるため、ルータを経由する必要がありません。
次に送信元の所属するサブネット外との通信ですが、こちらは逆にルータを経由しての通信が必要となり、このときにルータはサブネットに紐付けられたルートテーブルを参照してルーティングを行います。
実はサブネットを作成すると、下の図のようにVPC作成時に作られるデフォルトルートテーブルが自動で紐付けられます。
加えて、このルートテーブルにはローカルルートと呼ばれるルート情報がデフォルトで含まれています。

上図のデフォルトルートテーブルのローカルルート情報を見ていきましょう。
ここでようやく送信先とターゲットというキーワードが出てきました。
それぞれ下記のような意味を持ちます。
- 送信先(Destination):
ルーティング対象のIPアドレス範囲、すなわちCIDRブロックを指します。デフォルトルートテーブルでは、送信先としてVPCのCIDRブロック(例: 10.0.0.0/16)がlocalルートとして設定されています。このルートはVPC内のリソース間の通信を許可するためのものです。 - ターゲット(Target):
送信先ネットワークにトラフィックを送信するためのゲートウェイやインターフェイスを指します。デフォルトルートテーブルにおいて、ターゲットとして指定されているのはlocalです。これは外部のゲートウェイやインターフェイスを経由せずに直接ルーティングされることを意味します。
つまり、上記のデフォルトルートテーブルの意味は、 VPC内のネットワークを経由(ターゲット)して、同じVPCである[10.0.0.0/16] 宛(送信先)にトラフィックを送信するということになります。
[補足]インターネットと通信をするためには?
上記ではサブネット間での通信を題材に紹介しましたが、
サブネットからインターネットに出るためのルートテーブルの設定も見ていきたいと思います。
下記のようにパブリックサブネットからインターネットにアクセスしたい要件があったとします。
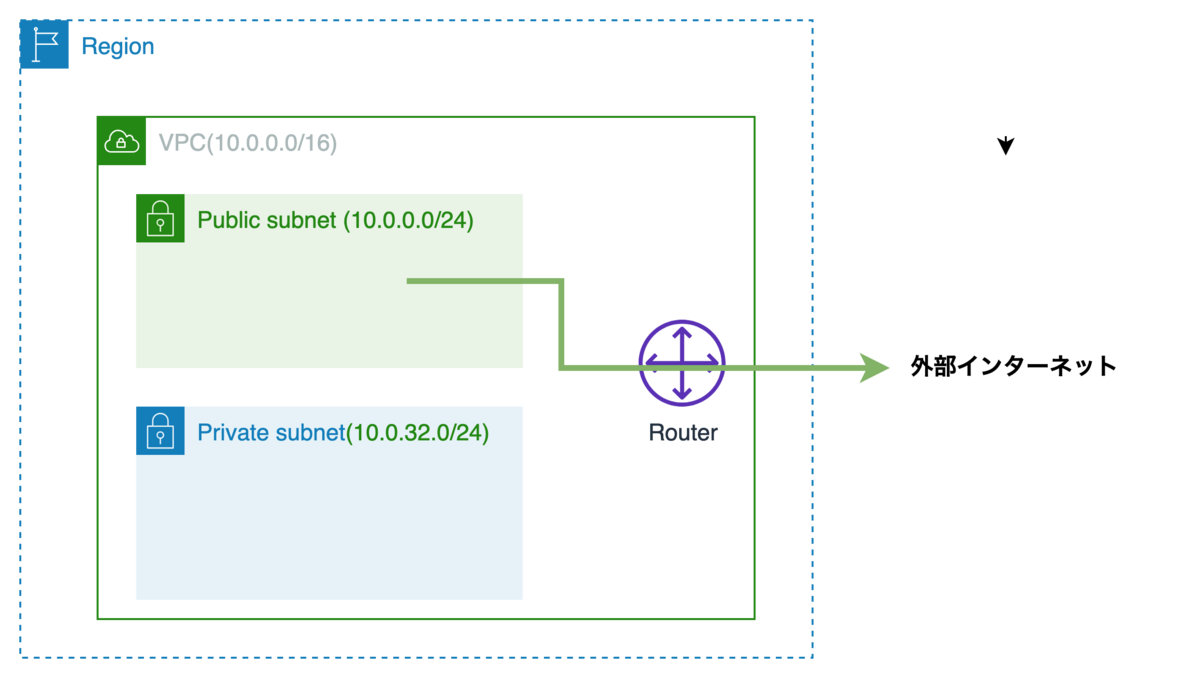 先に紹介した通り、インターネットとアクセスさせるためには、ルートテーブルに経路を追加する必要があります。
先に紹介した通り、インターネットとアクセスさせるためには、ルートテーブルに経路を追加する必要があります。
今回、既存のルートテーブルを編集してしまうと、同一のルートテーブルが紐づいているプライベートサブネットも外部インターネットに通信できるようになってしまうため、新規のルートテーブルを作成します。
次に、新しいルートテーブルを作成し、パブリックサブネットに関連付けます。
作成したルートテーブルには以下のルート情報を追加します。
- 送信先・・・すべてのIPv4の宛先(0.0.0.0/0)
- ターゲット・・・事前に作成したインターネットゲートウェイ(igw-xxxxxx)
※あらかじめ、インターネットゲートウェイを作成しておく必要があります
追加した場合の構成は下記のようになります。
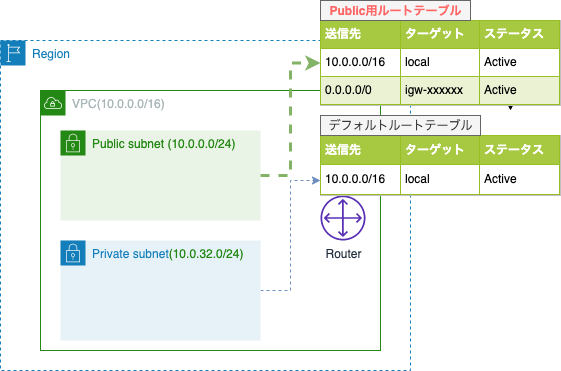
この状態で、パブリックサブネットからインターネットにアクセスをしようとすると、ルータはルートテーブルの送信先エントリの中から、トラフィックの宛先IPアドレスに一致するものを探します。
今回追加したルートの0.0.0.0/0はすべてのIPv4のアドレスを意味するCIDRブロックですので、他に一致するブロックがない場合はこのルートが選択されます。
0.0.0.0/0のターゲットがインターネットゲートウェイに設定されているので、トラフィックはこのゲートウェイを経由してインターネットに接続します。
以上がインターネットに接続するためのルートテーブルの設定についてです。
まとめ
今回、VPCのルートテーブルにおける「送信先」と「ターゲット」の役割を詳しく見てきました。特に、VPC内の通信をスムーズに行う「local」ターゲットや、サブネットとの関連付けについてのポイントを紹介しました。これが皆さんのAWS内の通信の流れや仕組みについての理解の一助となれば幸いです。
AWS reInvent2022で発表されたAWS Application Composerを試してみました

こんにちは。 先日のAWS re:Invent 2022で CTOのWerner VogelsよりAWS Application Composerの発表がありました。
Application Composerにより、サーバレスアプリケーションを構築する際に ビジュアルデザイナー上でのリソースを設計、テンプレートコードの自動生成が可能になります。
今回は本サービスを使用することで、サーバレスアプリの開発体験がどのように変わるのか検証してみました。
AWS Application Composerとは
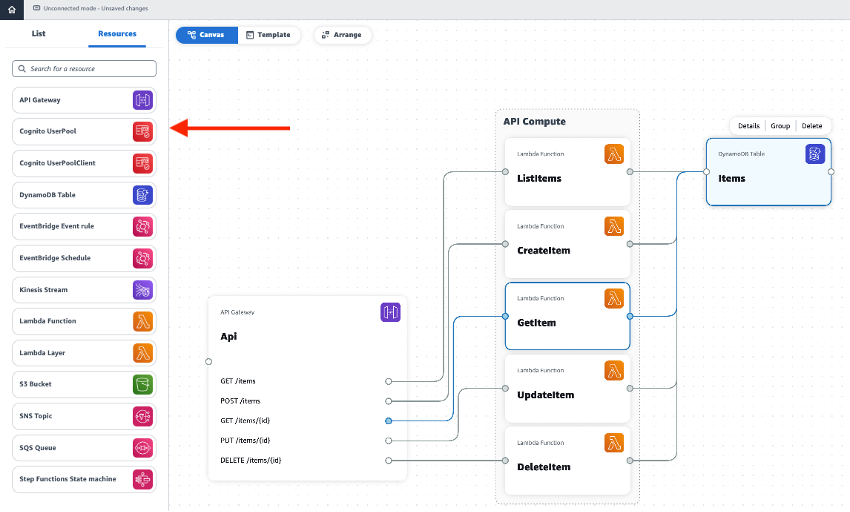
AWS Application Composerは、複数のAWSサービスからサーバーレスアプリケーションを構築するために使用できるビジュアルデザイナーです。 コンソール上に表示されたキャンバス上でAWSリソースをドラッグアンドドロップで選択、 リソース間の接続をすることで、アプリケーションアーキテクチャを簡単に設計することができます。
さらに設計したアーキテクチャからAWSのベストプラクティスに則ったインフラストラクチャー・アズ・コード(IaC)テンプレートを自動生成することができます。
今まで、サーバレスアプリケーションを作る際にはアーキテクチャの設計とテンプレートの作成を別々に行う必要がありましたが、 Application Composerを使うことによってテンプレートファイルの作成に時間を使う必要がなくなり、 その分、担当者は設計に集中できるようになります。
またCloudFormationの専門家がいなくてもサーバレスアプリケーションの構築が可能になることが期待されます。
実際に試してみた
それではプレビュー版がサポートされている東京リージョンで試していきます。 まずコンソール上でApplication Composerを開きます。 今回はデモ版を試すため、右上の「Open demo」をクリックします。
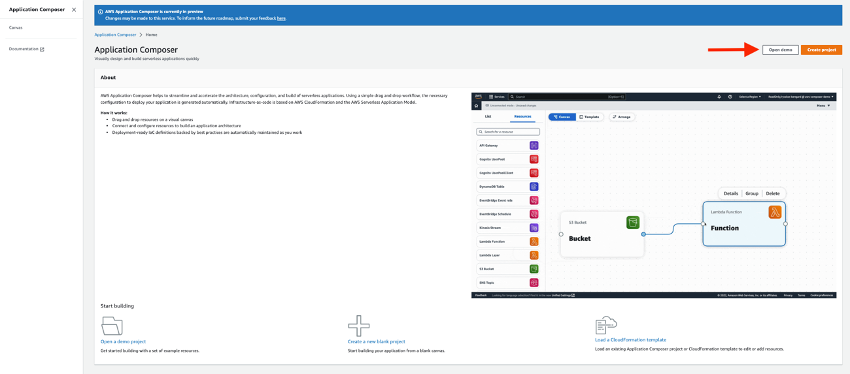
クリックすると、下記のようなオプション選択画面が表示されます。

ここでは接続タイプを「Connected」か「Unconnected」を選択します。 「Connected」を選択すると、自動的にテンプレートを含めたプロジェクトフォルダがローカルに保存され、 キャンバス上でコンポーネントを編集すると自動でローカルにも編集内容が同期されるようになります。 一方で「Unconnected」を選択すると同期されないため、テンプレートファイルのインポートとエクスポートを手動で行う必要があります。 今回は「Connected」を選択します。 次に「Select folder」ボタンをクリックして、ローカル環境で保存したい空のディレクトリを選択後、「Create」をクリックします。

ポップアップが表示されるので、「変更を保存」を選びます。
すると下記のようにデモアプリのアーキテクチャが既に作られたデザイナー画面が表示されます。
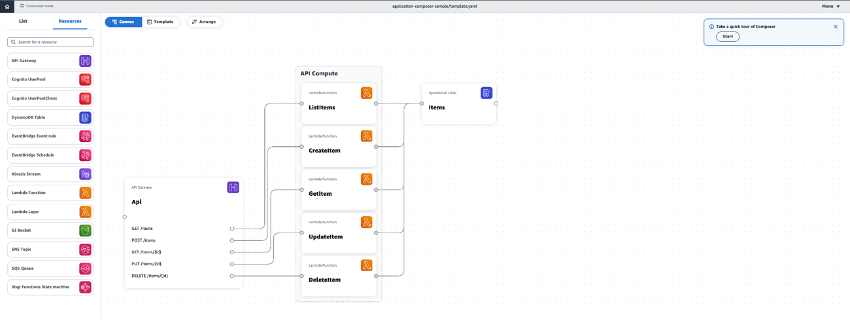
アーキテクチャの構成としてはシンプルなAPI Gateway, Lambda, DynamoDBの三層構成で、 各HTTPリクエストに応じたLambda関数を呼び出し、DynamoDBを操作するような作りとなっています。
ここで各コンポーネントを見ていきましょう。
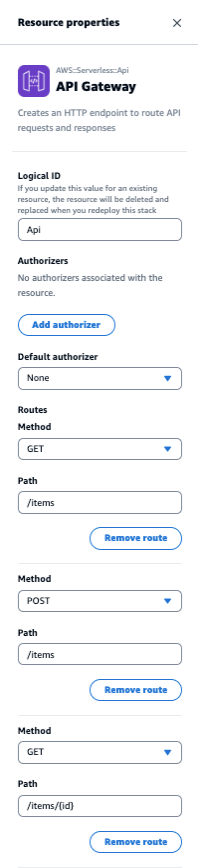
まずAPI Gatewayについてです。キャンバスに表示されたApiを選択し、Detailsをクリックしてみると右にAPI Gatewayのプロパティ画面が表示されます。
ここでHTTPルートの追加、編集、削除やAuthorizerの追加、CORSの設定等ができるようです。
次にLambdaです。同様にDetailsを見てみると、IDやランタイム、メモリ、ポリシーからLambda Layerまで基本的な設定はほとんどできるようでした。
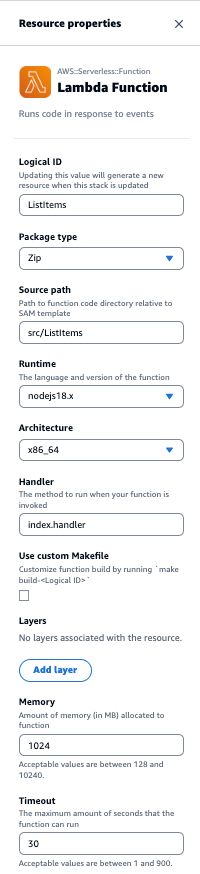
DynamoDBに関してはシンプルでキーの定義設定のみができるようです。キャパシティユニットやセカンダリインデックスの設定はまだサポート外のようですね。
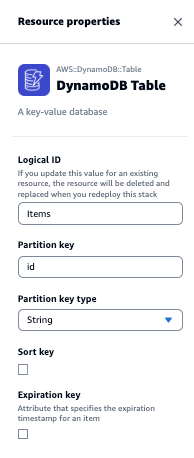
次にサービス間のコネクタ定義を見てみましょう。
コネクタを作ることでどのようにテンプレートが書き変わるのかを見たいため、デモで作成されたコネクタを一旦削除してみます。下記のようにコネクタを選択すると「Disconnect」ボタンが表示されるので、クリックしてすべてのコネクタを削除してみます。

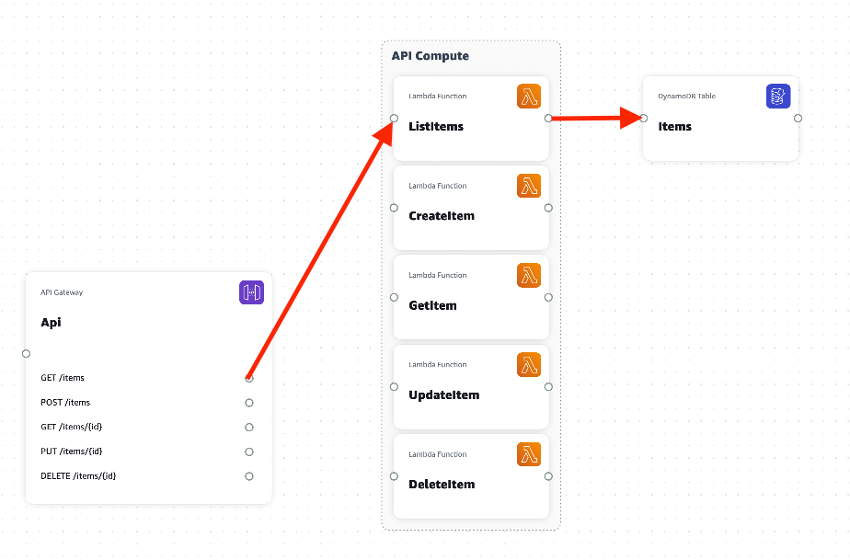
次にサービス間でコネクタを再作成してみます。下記のようにコンポーネントに付いている端子をドラッグして、API GatewayのGET /itemsとLambdaのListItems関数、ListItems関数とDynamoDBのitemsテーブルをつなげてみます。
次に画面左上部の「Template」タブを選択して、変更されたテンプレートファイルを確認してみます。
まずAPI Gatewayの定義を見ると、コネクタを作成したパス、メソッドにLambdaを呼び出す定義が追加されたことがわかります。

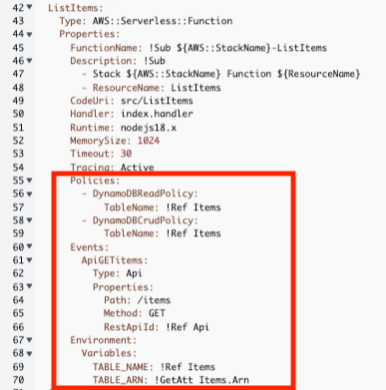
次にLambdaのListItemsの定義を見てみます。 赤枠で囲っている箇所が修正されており、EventsにはAPIのパス、メソッド定義が追加され、 Policies、EnvironmentにはDynamoDBにアクセスするための定義が追加されました。
ここでDynamoDBのポリシーについては注意が必要です。 テンプレートファイルを見てみると過去に紐付けたReadPolicyが削除されずに残ってしまっていたり、 今回紐付けたポリシーがCRUDポリシーになってしまっていたりするため、ここは手動で修正をします。
このようにリソースをキャンバス上で動かすだけでテンプレートファイルを簡単に書き換えることができました。
なお現在対応しているサービスについてですが、下記の左側の「Resources」に表示されているサービスだけのようです。
なお「Resources」には表示されていませんが、隠しリソースとしてそれらを含むテンプレートをロードすると、キャンバス上に表示されるようなサービスがあるようです。 現在、隠しリソースの例としては、以下のようなものがあります。 - AWS::ECS::TaskDefinition - AWS::CloudFront::Function - AWS::CloudFront::Distribution
ただし、機能がApplication Composerで完全にサポートされているわけではないそうなので注意が必要です。
次にこの作成されたアーキテクチャをデプロイしてみます。 先に設定したローカルのディレクトリを参照すると、下記のようにテンプレートやLambdaリソース、AWS SAMの設定ファイルが読み込まれていることがわかります。
ではこのリソースをAWS SAMを使用してデプロイしてみましょう。 AWS Serverless Application Model (AWS SAM) とは、AWS でサーバレスアプリケーションを構築するために使用できるオープンソースのフレームワークです。
SAM CLIが未インストールの場合は以下に記載の手順でインストールを行います。 https://docs.aws.amazon.com/ja_jp/serverless-application-model/latest/developerguide/serverless-sam-cli-install.html
インストール後、コマンドラインインターフェース上でプロジェクトのルートディレクトリに移動し、以下のコマンドを実行し、テンプレートをビルドします。
$ sam build -t template.yaml
成功の場合はBuild Suceededと表示されます。続いてデプロイを行います。 なお、Lambdaパッケージを保存するS3バケットが必要なため作成しておきます。
$ aws s3api create-bucket --bucket {bucket-name}--region ap-northeast-1 --create-bucket-configuration LocationConstraint=ap-northeast-1
上記で作成したバケット名を設定し、デプロイします。
$ sam deploy --s3-bucket {bucket-name}
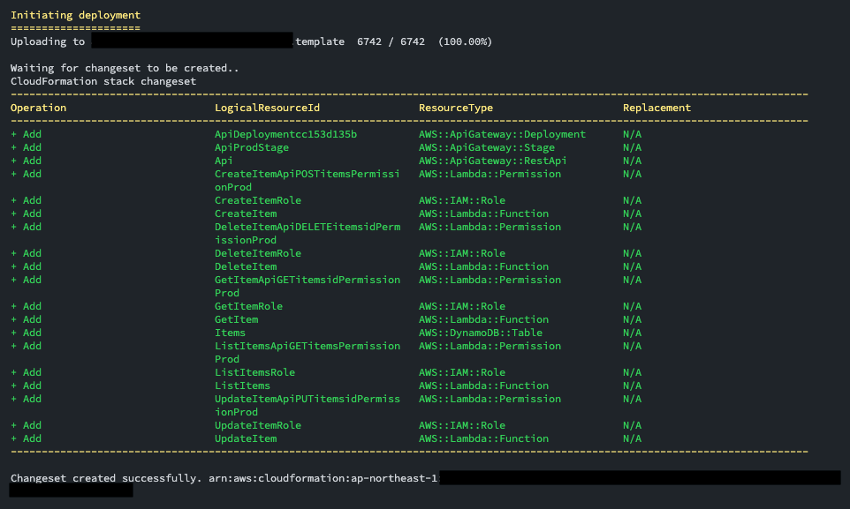
コマンド実行後、出力されるログを見ると、下記のようにリソースが作られているのがわかります。完了まで待ちましょう。
完了後、それぞれのリソースがデプロイされたかをAWSコンソール上で確認してみます。

Lambda

DynamoDB

それぞれ作成されていることが確認できました。 疎通テストを行いたい場合は、作成されたAPI Gatewayリソースのステージに記載されたURLにリクエストを送信することで確認ができます。
試した後は必ず、プロジェクトのルートディレクトリ上で下記のSAMコマンドを実行し、リソースを削除しましょう。
$ sam delete
さいごに
今回、Application Composerを試してみて、サーバレスアプリケーションの開発体験がどのように変わるのか確かめてみました。 個人的には今回くらいのシンプルな構成であれば、自動生成されたテンプレートファイルがそのまま使用できるため、構築時間の短縮に繋がるのではないかと思いました。 今後、対応リソースの追加や設定プロパティの追加されることによって、Application Composer上でできることが増え、サーバレスアプリケーションがより一層かんたんになっていくことを期待したいです。
AWS CodeCommitとJenkinsでiOSのCI/CD環境を作る
始めに
最近、iOSのアプリ開発に関わることになり、とある事情からiOSのCI/CD環境をローカルのMac端末で構築する必要がありました。
類似の事例をWebで探したのですが、該当する事例は少なかったので、備忘のためにも手順を本記事で紹介したいと思います。
1. iOSのCI/CDについて
現在、iOSアプリのCI/CDとして、利用できそうな方法は以下のとおりです。
特に制約がなければ、SaaSに記載したサービスを使用すれば十分です。
しかし、今回リポジトリ管理で使用してAWS CodeCommitをサポートするSaaSが存在しなかったことや、とある理由からでSaaSが使用できないという制約が存在したことから、泣く泣くCI/CDを時前で構築することとなりました...
このような背景から、必然的にMac OSがインストールされたサーバの用意が不可欠となり、Xcode Cloud、Macインスタンス、Mac端末から選択する必要がありました。
まずXcode Cloudについてですが、こちらもSaaSの理由と同様にCodeCommitとの連携がサポートされていなかったため、今回は候補から外しました。
次にMacインスタンスについてですが、自前でCI/CD環境を一から作る必要があるものの、CodeCommitとの連携もJenkinsを使用すれば可能です。
しかし、問題としては料金がかかりすぎてしまうことで、Macインスタンスの最小割当期間が24時間と設定されており、一回起動あたり最低でも約4000円ほどかかってしまいます(Macインスタンスは、実際には物理マシン自体が割り当てられているので、この料金も頷けます)。
上記の理由から、消去法でローカルのMac端末上でJenkinsでCI/CD環境を構築する方針となりました。
次に、この方針に沿って実際に構築した内容を紹介したいと思います。
2. 全体構成
全体構成は以下の通りです。 CodeCommitにソースがPushされると、
Mac上のJenkinsサーバのジョブが更新を検知後、大きく分けて、下記の順番で処理が実行されます。
ソースを取り込み → 単体テスト → UIテスト → ビルド → Firebaseにアップロード
上記のフローの中で、単体テスト完了後にCoverage情報をSlackに通知するようにしており、
UIテストで取得したアプリ画面のキャプチャ情報はS3にアップロードするようにしています。
最後にFirebaseにアップロードが完了するとSlackに通知されるようにしています。

3. 手順
3-1. 前提
- Apple Developer Programに登録してあること(有料版ではないとビルドファイルが作成できません)
- Apple Developer内でAd hoc配信用の証明書、プロビジョニングプロファイルを作成済みであること
- Mac端末を用意していること
- Macに以下がインストール済みであること
- AWSアカウントを用意してあること
- AWS CodeCommitでリポジトリが作成済みであること
3-2. Firebaseの設定
今回はFirebase App Distributionを使用して配信します。
まずはFirebaseをAppleプロジェクトに追加します。
こちらの公式の記事を参考にしてください。
3-3. Fastlaneファイルの作成
次にfastlaneの設定を行います。
設定はこちらの公式の記事を参考にしてください。
ここで注意いただきたいのが、今回自動で配信を行うため、
手順2のFirebaseの認証方法はサービスアカウントの認証情報を使用するにしてください。 
またご参考までに私が作成したFastfileは以下の通りです。
3-4. (オプション)fastlane snapshotの追加
XCUIテストを実行し、各アプリ画面のスクリーンショットを作成したい場合、 fastlane snapshot機能を使用します。
導入の手順は以下が参考になります。 an.hatenablog.jp
また私は証跡をS3にアップロードするようにしています。
fastlaneのすべての処理が終わったタイミングでS3に本日の日付のディレクトリを作成し、 アップロードするようにしておりました(下のソースのshの箇所)。
※S3にアップロードするためには事前にバケットを事前に作成しておく必要があります。
3-5. Jenkinsのセットアップ
次にJenkinsのセットアップを行います。 Jenkinsをインストールをインストールすために、 Terminalを開き以下のコマンドを実行します。
brew install jenkins
Jenkinsを起動するために以下のコマンドを実行します。
brew services start jenkins
http://localhost:8080にアクセスすると準備中の画面が表示されます。 
画面の中部に記載されているパスにパスワードが保存されているため、 以下のコマンドで表示されたパスワードをフォームに入力する。
$ cat /Users/[username]/.jenkins/secrets/initialAdminPassword
Customize JenkinsはInstall suggested pluginsのままで。 後ほどGit, CodeCommit用のプラグインをインストールします。

次に進むと、セットアップのステータスが表示されます。 
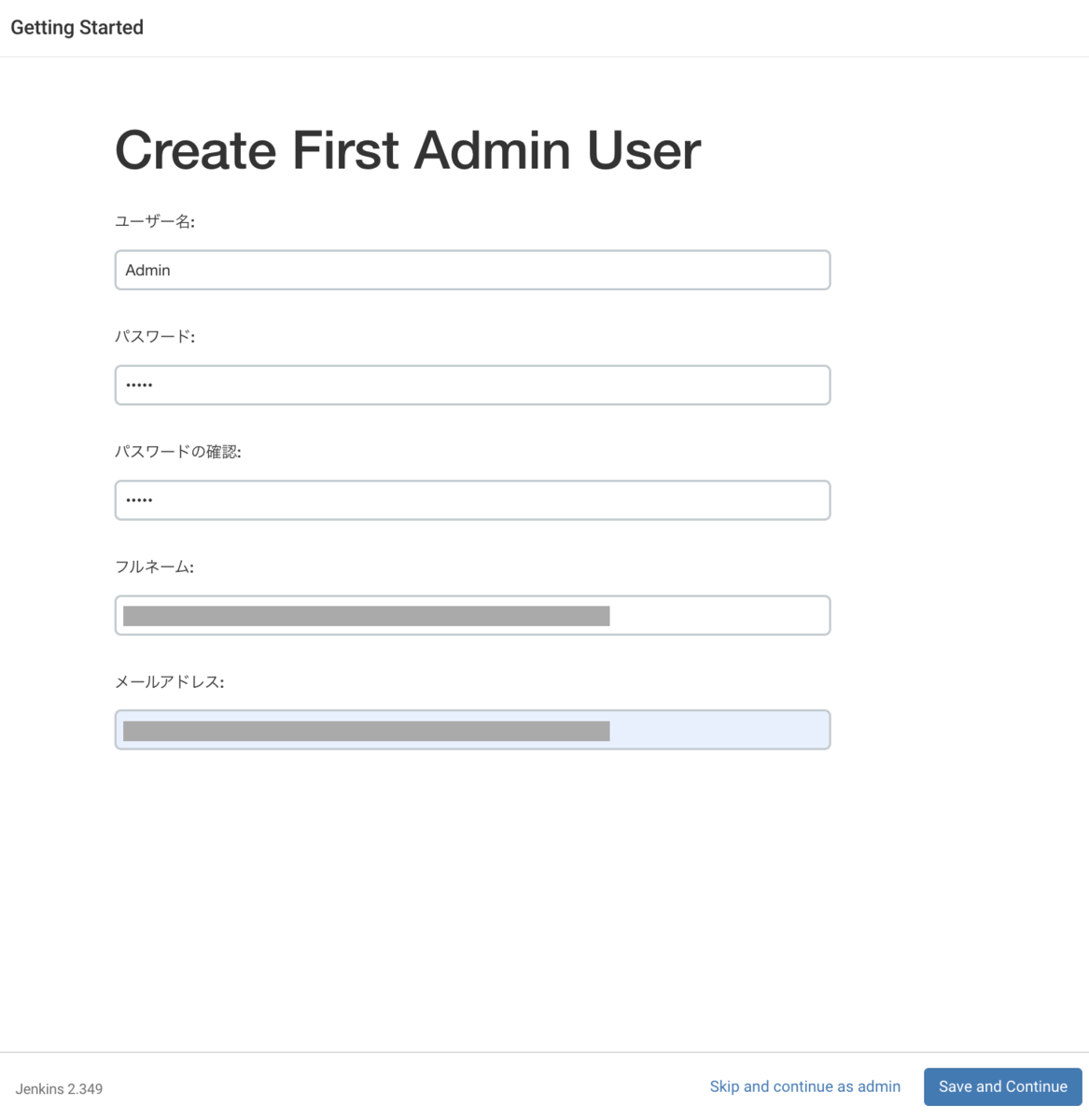
セットアップが終了すると、ユーザ登録画面に移りますので、
ユーザ情報を入力します。
次の画面では必要があればJenkinsのURLを変更します。 特に変更する必要がないのでこのままで次に進みます。

Start using Jenkinsをクリック 
ホーム画面に遷移します。 まずは環境設定を行います。 
左のメニューから「Jenkinsの管理」を選択 管理画面で「システムの設定」をクリック 
システム設定ページでグローバルプロパティにて環境変数を選択→追加ボタンをクリック。
キーにはPATHを値には$PATH:/usr/local/binを入力する。
※git-remote-codecommitが格納されているディレクトリのパスを指定する必要があります。わからなければ以下を実行。
which git-remote-codecommit
入力後「保存」をクリック。 
3-6. Jenkinsでジョブの作成
トップページに戻り、「Create a job」を入力 
ジョブ名を入力します。
ビルドの種類は「フリースタイル・プロジェクトのビルド」を選択したまま、「OK」をクリック。 
Generalには特に設定は不要。 
ソースコード管理ではGitを選択後、リポジトリURLにはcodecommit://[リポジトリ名]を入力。
ビルドするブランチには今回のビルド対象となるブランチ名を入力してください。
その他の設定はデフォルトで大丈夫です。 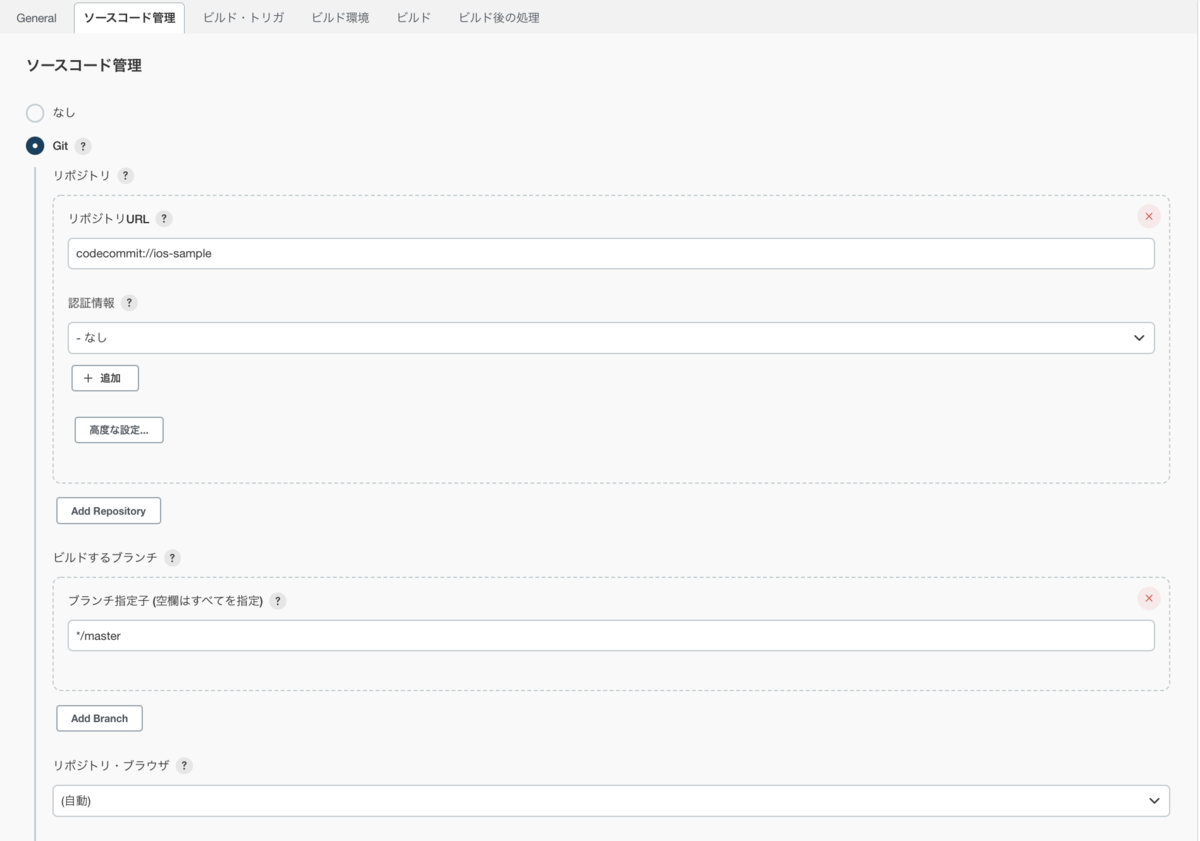
ビルド・トリガには今回は定期的にCommitがあるかをポーリングする方式にするため SCMをポーリングを選択して、Cron式を入力します。
今回は2分に一度ポーリングする方式にしたため、H/02 * * * *としました。 
ビルド環境はデフォルトのままです。 
次にビルドするために必要なコマンドを設定します。
「ビルド手順の追加」→「シェルの実行」を選択
GOOGLE_APPLICATION_CREDENTIALSのパスはfirebase-app-dist.jsonを格納したパスに変更してください。
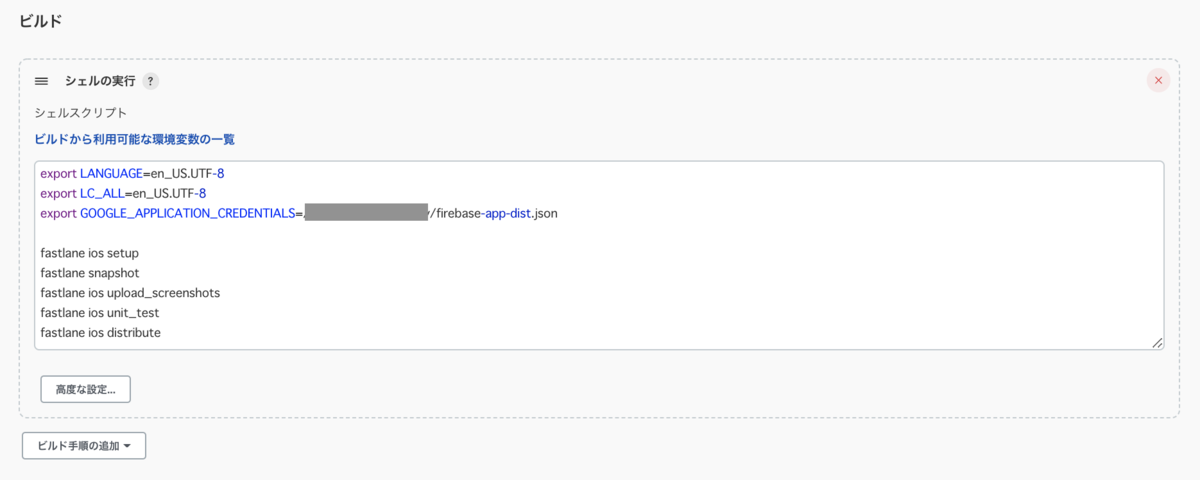
export LANGUAGE=en_US.UTF-8 export LC_ALL=en_US.UTF-8 export GOOGLE_APPLICATION_CREDENTIALS=/PATH/firebase-app-dist.json fastlane ios setup # 不要であればコメントアウト fastlane snapshot # 不要であればコメントアウト fastlane ios upload_screenshots # 不要であればコメントアウト fastlane ios unit_test fastlane ios distribute
3-5. CodeCommit, S3へのアクセス設定
CodeCommitにアクセスするためにgit-remote-codecommitを使用します。 git-remote-codecommitの導入手順は以下をご確認ください。 Git 認証情報を使用した HTTPS ユーザーのセットアップ - AWS CodeCommit
またS3へのアクセスはIAMプロファイルの設定を行う必要がありますが、上記の手順で プロファイルの設定も行うため、個別設定は不要となります。
検証
それではどのように動作するのかをお見せいたします。
CodeCommitのブランチにPushをすると、 Jenkins上で対象のプロジェクトを確認すると右下の履歴でジョブが実行中であることがわかります。 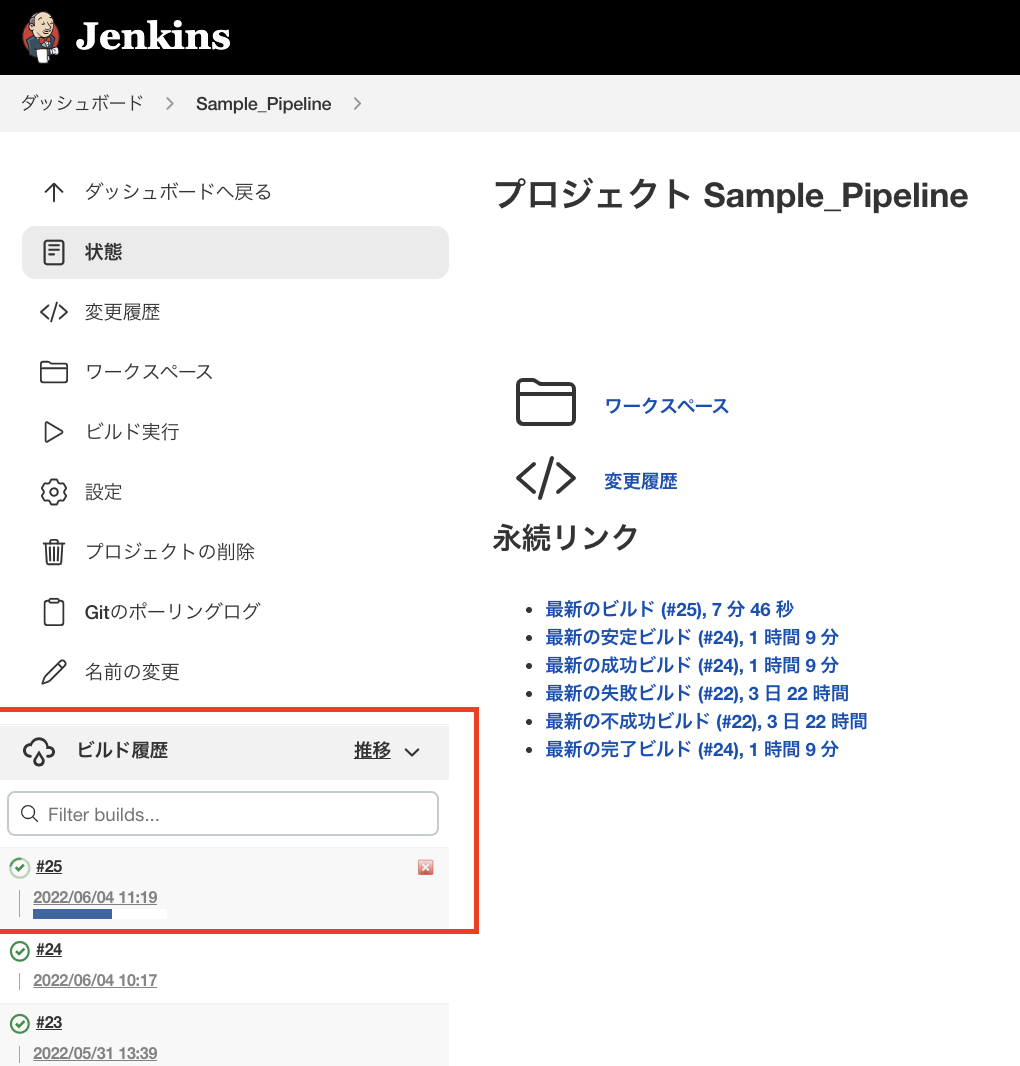
ジョブが失敗していた場合は、対象の履歴からコンソール出力を見ることでデバッグログを見ることができます。
ジョブの完了後、Firebase App Distributionにアップロードされているかを確認します。
Firebaseコンソールにログインをして、App Distiributionを開くと、最新版がアップロードことが確認できました!

またFastlane内で指定したメールアドレスにも配信メールが届いており、 そのリンクからアプリをダウンロードすることができました!
ちなみにSlackにはこのように各プロセスが完了すると通知が届くようになっています。
xcovを設定しているとUIテストのカバレッジも通知してくれます。

まとめ
今回はMac端末をビルドサーバとするような構成でのiOS CI/CDパイプラインを紹介いたしました。 本来であれば、手間の少ないSaaSを使うことがベターだと思いますが、 SaaSを使えないような制約がある場合は、今回の構成が参考になるかもしれません。
Google Cloud Logging上の特定のログをメールで通知しよう
お久しぶりです。
最近、Google Cloudを使用する機会が多く、 このサービスはAWSでいうと〇〇やなと脳内変換しながら作業しています。
さて今回はGoogle Cloud Logging上に集計された特定のログをメールやSlackで通知する方法をご紹介したいと思います。
手順1 通知先を設定
まずは通知先を登録しましょう。
1.Cloud Console で、[Monitoring] に移動します
2.Monitoring のナビゲーション パネルで、notifications [アラート] をクリックします。
3.[Edit notification channels] をクリックします。

4.チャネルの種類を見つけて [ADD NEW] をクリックし、情報を登録します。今回はEmailで通知しますので、Emailの[ADD NEW]をクリックします。
通知したいメールアドレスと表示名を入力し、[保存]をクリックします。 
手順2 フィルタリング用のクエリを作成
続いて、通知アラートを作成します。
1.Cloud Console で、[ロギング] に移動します

2.フィルタリング用のクエリを作成します。
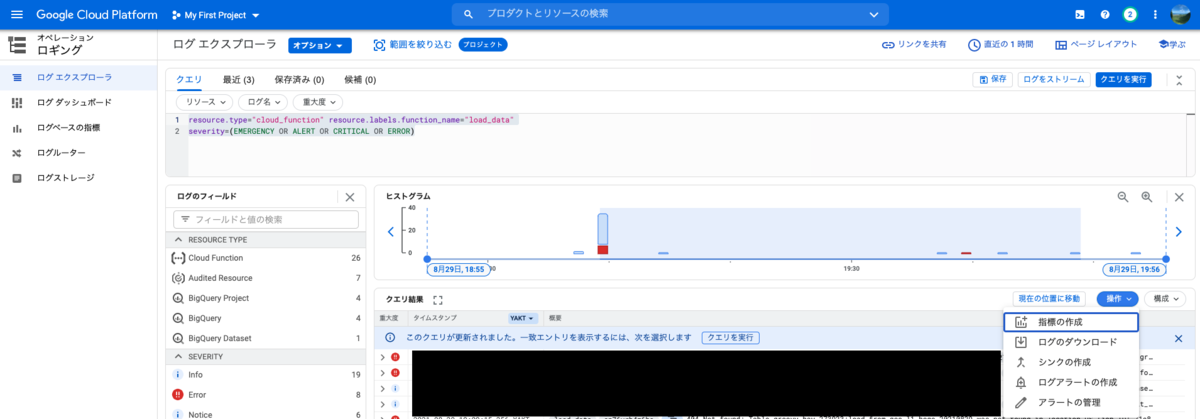
アラート設定の際に特定のログにフィルタリングするためのクエリ情報が必要となります。 上記のエクスプローラ上で事前にクエリを作成しておきましょう。 クエリ入力欄の上部に[リソース][ログ名][重大度]から絞り込むだけで、クエリが自動で作成されるので活用しましょう。 私の場合、Cloud functionsで出力されるエラーのうち、エラー以上のものを通知したかったため、 リソースをCloud functionsの作成した関数を追加し、重大度は[緊急][アラート][重大][エラー]にチェックつけ追加しました。 

作成されたクエリは以下の通りです。
resource.type="cloud_function" resource.labels.function_name="sample" severity=(EMERGENCY OR ALERT OR CRITICAL OR ERROR)
このクエリを実行し、フィルタリングされたログ情報を表示しましょう。
手順3 アラートの作成
1.ログエクスプローラ画面の右真ん中付近の[操作]ボタンをクリック。ログアラートの作成をクリックします。
2.アラート情報を入力します。
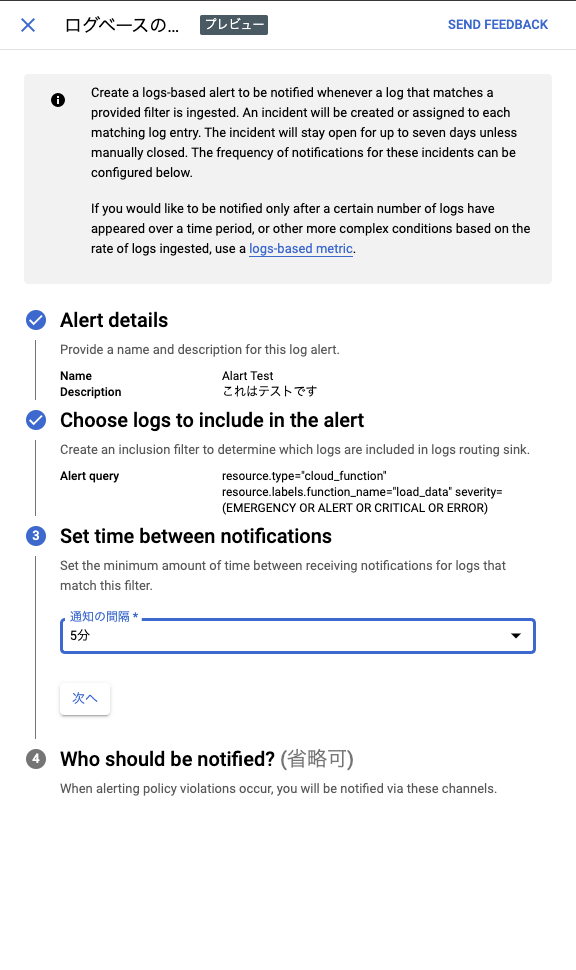
①Alert detailでアラート名とアラートの内容を入力し、[次へ]をクリックします。

②Choose logs to include in the alertでは事前にクエリが実行されていればそのクエリ式が既に入力されているはずです。 そのまま[次へ]を押下しましょう。

③Set time between notificationsでは通知の間隔を指定します。好きな間隔を指定し、[次へ]をクリックします。
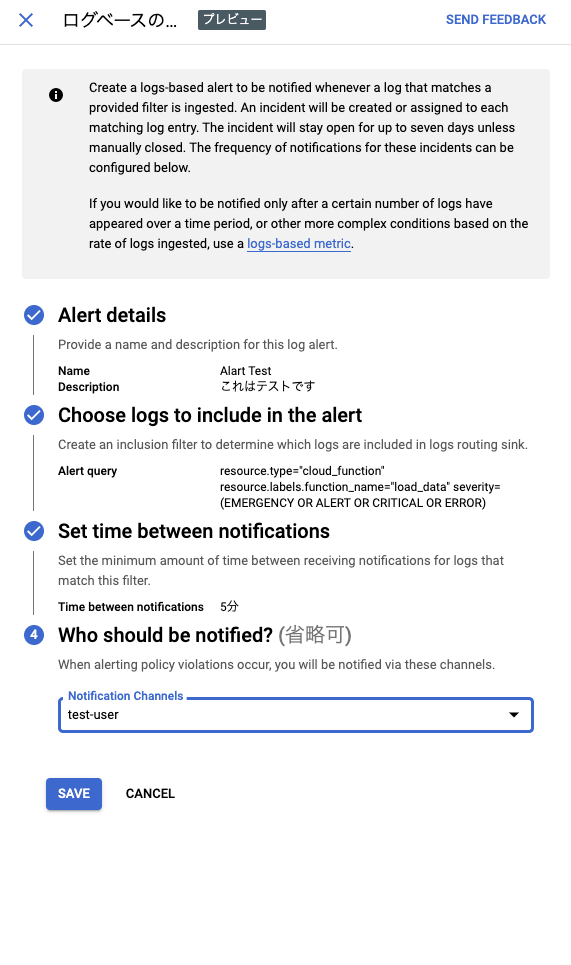
④Who should be notified? で手順1にて作成したチャネルを指定しましょう。指定後、[SAVE]をクリックします。
これで設定は完了です。 実際にテストしてみましょう。
私の場合はCloud functionを設定したので、Cloud functionで意図的にアラートが発生させてみます。
エラー発生後、およそ30秒ほどでメールがきました! 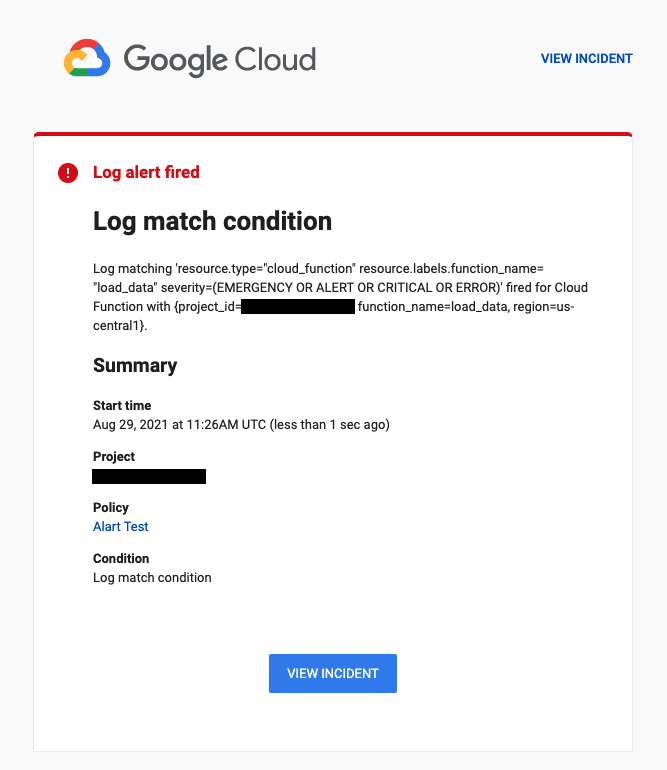
最後に
今回はGoogle Cloud Logging上の特定のログをユーザに通知する方法を試してみました。 ログアラートの箇所にベータ版と記載してあったので、もしかしたら今後設定方法が変わるかもしれませんが、 同じような設定をしたい方ぜひとも試してみてください!